性能
性能优化策略
- content方面
- 减少HTTP请求:合并文件、CSS精灵、inline Image
- 减少DNS查询:DNS查询完成之前浏览器不能从这个主机下载任何任何文件。方法:DNS缓存、将资源分布到恰当数量的主机名,平衡并行下载和DNS查询
- 避免重定向:多余的中间访问
- 使Ajax可缓存
- 非必须组件延迟加载
- 未来所需组件预加载
- 减少DOM元素数量
- 将资源放到不同的域下:浏览器同时从一个域下载资源的数目有限,增加域可以提高并行下载量
- 减少iframe数量
- 不要404
- Server方面
- 使用CDN
- 添加Expires或者Cache-Control响应头
- 对组件使用Gzip压缩
- 配置ETag
- Flush Buffer Early
- Ajax使用GET进行请求
- 避免空src的img标签
- Cookie方面
- 减小cookie大小
- 引入资源的域名不要包含cookie
- css方面
- 将样式表放到页面顶部
- 不使用CSS表达式
- 使用
<link>不使用@import - 不使用IE的Filter
- Javascript方面
- 将脚本放到页面底部
- 将javascript和css从外部引入
- 压缩javascript和css
- 删除不需要的脚本
- 减少DOM访问
- 合理设计事件监听器
- 图片方面
- 优化图片:根据实际颜色需要选择色深、压缩
- 优化css精灵
- 不要在HTML中拉伸图片
- 保证favicon.ico小并且可缓存
- 移动方面
- 保证组件小于25k
- Pack Components into a Multipart Document
页面加载优化
「页面加载链路+流程优化+协作方」的多级分类思考
- 页面启动
- service worker 缓存重要的静态资源
- 页面保活
- 资源加载
- 网络连接
- NDS
- 减少 NDS 解析
- NDA 预解析
- HTTP
- 开启 HTTP2 多路复用
- 优化核心请求链路
- HTML 加载
- 内容优化
- 代码压缩
- 代码精简(tailwindcss)
- 服务端渲染 SSG
- 流程优化
- 服务端渲染 SSR
- 流式渲染
- 预渲染
- 静态资源加载
- 内容优化
- JS、CSS 代码压缩
- 均衡资源包体积:复用代码抽离为一份资源打包、同时开启
- 精简代码
- 雪碧图
- 动态图片降质量
- 动态 polyfill (根据浏览器的支持情况,动态加载需要的 polyfill(填充)脚本)
- 不常变的资源单独打包
- 根据浏览器版本打包, 高版本浏览器, 直接使用 es6 作为输出文件
- 流程优化
- 配置前端缓存: 资源、请求
- 使用 CDN
- CDN 优化
- 协调资源加载优先级
- 动态资源转静态 CDN 链接加载(例如大图片等)
- 静态资源使用 service worker 离线存储
- 非首屏资源懒加载
- 资源和业务请求预加载
- 微前端加载应用
- 微组件加载核心模块资源
- 代码执行
- 减少执行
- 减少重复渲染
- 大体量计算场景, 尽量使用缓存函数
- 使用防抖节流
- 速度提升
- 使用 worker 多线程加速
- 充分利用异步请求的线下之间来进行核心代码的加载或者执行
- wasm 处理大量计算场景
- 渲染高耗时场景, 迁移到 canvas 、虚拟 dom 等
- 动态渲染:动态渲染可视区内容, 例如图片懒加载等;
- 流程优化
- 非首屏模块, 延迟加载与渲染
- longtask 任务拆分执行
- 利用请求闲暇时间, 请求后续页面资源
- 数据获取
- 内容优化
- 减少请求、合并请求、BFF
- 首屏数据使用模板注入到前端应用
- 流程优化
- 数据预请求
- 常量数据缓存
- 非首屏请求,延迟到首屏加载完成之后请求
- 请求并行
- 渲染相关
- 虚拟列表
- 延迟渲染
- 减少重绘重排
- 图片预加载到内存
常见性能指标获取方式
相关性能指标问题, 可以看这个文章:https://github.com/pro-collection/interview-question/issues/515
指标所反映的用户体验 下表概述了我们的性能指标如何对应到我们的问题之上:
开始了吗?
- 首次绘制、首次内容绘制 First Paint (FP) / First Contentful Paint (FCP)
有用吗?
- 首次有效绘制、主要元素时间点 First Meaningful Paint (FMP) / Hero Element Timing
能用吗?
- 可交互时间点 Time to Interactive (TTI)
好用吗?
- 慢会话 Long Tasks (从技术上来讲应该是:没有慢会话)
页面何时开始渲染 - FP & FCP
这两个指标,我们可以通过 performance.getEntry、performance.getEntriesByName、performanceObserver 来获取。
performance.getEntries().filter(item => item.name === 'first-paint')[0] // 获取 FP 时间
performance.getEntries().filter(item => item.name === 'first-contentful-paint')[0] // 获取 FCP 时间
performance.getEntriesByName('first-paint') // 获取 FP 时间
performance.getEntriesByName('first-contentful-paint') // 获取 FCP 时间
// 也可以通过 performanceObserver 的方式获取
const observer = new PerformanceObserver(function (list, obj) {
const entries = list.getEntries()
entries.forEach(item => {
if (item.name === 'first-paint') {
// ...
}
if (item.name === 'first-contentful-paint') {
// ...
}
})
})
observer.observe({ type: 'paint' })
页面何时渲染主要内容 - FMP & SI & LCP
FMP, 是一个已经废弃的性能指标。在实践过程中,由于 FMP 对页面加载的微小差异过于敏感,经常会出现结果不一致的情况。此外,该指标的定义依赖于特定于浏览器的实现细节,这意味着它不能标准化,也不能在所有 Web 浏览器中实现。目前,官方并没有提供有效的获取 FMP 的接口,因此性能分析的时候不再使用这个指标。
SI 和 FMP 一样,官方也没有提供有效的获取接口,只能通过 lighthouse 面板来查看,不作为 Sentry 等工具做性能分析的指标。
LCP,和 FMP 类似,但只聚焦页面首次加载时最大元素的绘制时间点,计算相对简单一些。通过 performanceObserver 这个接口,我们可以获取到 LCP 指标数据。
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
console.log('LCP candidate:', entry.startTime, entry)
}
}).observe({ type: 'largest-contentful-paint', buffered: true })
何时可以交互 - TTI & TBT
TTI, time to ineractive, 可交互时间, lighthouse 面板中的六大指标之一, 用于测量页面从开始加载到主要资源完成渲染,并能够快速、可靠地响应用户输入所需的时间, 值越小约好。
官方资料: TTI 。
和 FMP、SI 一样,官方并没有提供获取 TTI 的有效接口,只能通过 lighthouse 面板来查看。
计算方式人如下:
-
先进行 First Contentful Paint 首次内容绘制;
-
沿时间轴正向搜索时长至少为 5 秒的安静窗口,其中,安静窗口的定义为:没有长任务且不超过 2 个正在处理的网络请求;
-
沿时间轴反向搜索安静窗口之前的最后一个长任务,如果没有找到长任务,则在 FCP 步骤停止执行。
-
TTI 是安静窗口之前最后一个长任务的结束时间(如果没有找到长任务,则与 FCP 值相同)。
理解计算过程如下图:
TTI 表示的是完全可交互的时间, 每个 web 系统, 对 TTI 时间定义可能并不一定相同, 上面只是提供一个计算较为通用的 TTI 的一个方式。
交互是否有延迟 - FID & MPFID & Long Task
FID 和 MPFID 可用来衡量用户首次交互延迟的情况,Long Task 用来衡量用户在使用应用的过程中遇到的延迟、阻塞情况。
FID,first input delay, 首次输入延迟,测量从用户第一次与页面交互(例如当他们单击链接、点按按钮或使用由 JavaScript 驱动的自定义控件)直到浏览器对交互作出响应,并实际能够开始处理事件处理程序所经过的时间。官方资料: FID。
FID 指标的值越小约好。通过 performanceObserver,我们可以获取到 FID 指标数据。
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
const delay = entry.processingStart - entry.startTime
console.log('FID candidate:', delay, entry)
}
}).observe({ type: 'first-input', buffered: true })
MPFID, Max Potential First Input Delay,最大潜在首次输入延迟,用于测量用户可能遇到的最坏情况的首次输入延迟。和 FMP 一样,这个指标已经被废弃不再使用。
Long Task,衡量用户在使用过程中遇到的交互延迟、阻塞情况。这个指标,可以告诉我们哪些任务执行耗费了 50ms 或更多时间。
new PerformanceObserver(function (list) {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
// ...
}
}).observe({ type: 'longtask' })
页面视觉是否有稳定 - CLS
CLS, Cumulative Layout Shift, 累积布局偏移,用于测量整个页面生命周期内发生的所有意外布局偏移中最大一连串的布局偏移情况。官方资料: CLS。
CLS, 值越小,表示页面视觉越稳定。通过 performanceObserver,我们可以获取到 CLS 指标数据。
new PerformanceObserver(function (list) {
const perfEntries = list.getEntries()
for (let i = 0; i < perfEntries.length; i++) {
// ...
}
}).observe({ type: 'layout-shift', buffered: true })
如何监控卡顿
- chrome 卡顿和设备刷新率是否有关?
- 通过 requestAnimationFrame 监控卡顿
- PerformanceObserver 监控长任务
常用性能指标
-
FCP 已废弃
-
LCP
-
INP
-
FID(First Input Delay) - 首次输入延迟
-
TTI(Time to Interactive) - 可交互时间
-
CLS(Cumulative Layout Shift) - 累积布局偏移
-
TTFB(Time to First Byte) - 首字节时间
-
TBT(Total Blocking Time) - 总阻塞时间
-
Front-end-De veloper-Interview-Questions/Performance Questions
性能的核心问题
- 什么样的性能指标最能度量人的感觉?
- 怎样才能从我们的真实用户中获取这些指标?
- 如何用我们所获取的指标来确定一个页面表现得是否「快」?
- 当我们得知用户所感知的真实性能表现后,我们应该如何做才能避免重蹈覆辙,并在未来提高性能表现?
以用户为中心的性能指标
开始了吗? 页面开始加载了吗?得到了服务端的回应吗?
有用吗? 有足够用户期望看到的内容被渲染出来了吗?
能用吗? 用户能够与我们的页面交互了吗?还是依然在加载?
好用吗? 交互是否流畅、自然、没有延迟与其他的干扰?
首次绘制(First Paint)和首次内容绘制(First Contentful Paint)
首次绘制(FP)和首次内容绘制(FCP)。在浏览器导航并渲染出像素点后,这些指标点立即被标记。 这些点对于用户而言十分重要,因为它回答了我们的第一个问题问题:开始了吗?
FP与FCP的主要区别在于,FP标记浏览器所渲染的任何与导航前内容不同的点,而FCP所标记的是来自于DOM中的内容,可能是文本、图片、SVG,甚至是canvas元素。
首次有效绘制(First Meaningful Pain)和主要元素时间点(Hero Element Timing)
首次有效绘制(FMP)回答了我们的问题:有用吗?对于现存的所有网页而言,我们不能去清晰地界定哪些元素的加载是「有用」的(因此目前尚无规范), 但是对于开发者他们自己而言,他们很容易知道页面的哪些部分对于用户而言是最为有用的。
这些页面中「最重要的部分」通常被称为主要元素。举一些例子,在YouTube的播放页面,播放器就是主要元素。在Twitter中可能是通知的图标,或者是第一条推文。在 天气应用中,主要元素应是指定位置的预测信息。在一个新闻站点中,它可能是摘要,或者是第一张插图。
网页中总有一部分内容的重要性大于其余的部分。如果这部分的内容能够很快地被加载出来,用户甚至都不会在意其余部分的加载情况。
可交互时间(TTI)
可交互时间(TTI)标记了你的页面已经呈现了画面,并且能够响应用户输入的时间点。页面不能响应用户输入有以下常见的原因:
- 将被JavaScript所操作的元素还未被加载出来;
- 一些慢会话阻塞了浏览器的主线程(如我们在上一部分所描述的)
TTI所记录实际上是页面的JavaScript完成了初始化,主线程处于空闲的时间点。
long tasks
浏览器像是单线程的。 某些情况下,一些任务将可能会花费很长的时间来执行,如果这种情况发生了,主线程阻塞,剩下的任务只能在队列中等待。
用户所感知到的可能是输入的延迟,或者是哐当一下全部出现。这些是当今网页糟糕体验的主要来源。
Long Tasks API认为任何超过50毫秒的任务都可能存在潜在的问题,并将这些任务揭露给开发者。既然能够满足50毫秒内完成任务,也就能够符合RAIL在100毫秒内相应用户输入的要求。
指标所反映的用户体验
下表概述了我们的性能指标如何对应到我们的问题之上:
开始了吗?
- 首次绘制、首次内容绘制 First Paint (FP) / First Contentful Paint (FCP)
有用吗?
- 首次有效绘制、主要元素时间点 First Meaningful Paint (FMP) / Hero Element Timing
能用吗?
- 可交互时间点 Time to Interactive (TTI)
好用吗?
- 慢会话 Long Tasks (从技术上来讲应该是:没有慢会话)
获取指标
主要依赖浏览器提供的 api
PerformanceObserver 使用示范
要使用 PerformanceObserver,首先需要创建一个 PerformanceObserver 实例,并指定一个回调函数作为参数。回调函数将在性能事件触发时被调用。然后,通过 PerformanceObserver 的 observe() 方法去监听所关注的性能事件类型。
以下是一个使用 PerformanceObserver 的示例代码:
// 创建回调函数
function performanceCallback (list, observer) {
list.getEntries().forEach(entry => {
console.log(entry.name + ':' + entry.startTime)
})
}
// 创建 PerformanceObserver 实例
const observer = new PerformanceObserver(performanceCallback)
// 监听性能事件类型
observer.observe({ entryTypes: ['measure', 'paint'] })
在上面的代码中,定义了一个名为 performanceCallback 的回调函数,它接收两个参数:list 和 observer。list 参数是一个 PerformanceEntryList 对象,包含了所有触发的性能事件,可以通过 getEntries() 方法获取详细信息。observer 参数表示 PerformanceObserver 实例本身。
然后,通过 new PerformanceObserver(performanceCallback) 创建了一个 PerformanceObserver 实例,并将 performanceCallback 作为回调函数传递进去。
最后,通过 observer.observe({ entryTypes: ["measure", "paint"] }) 方法,指定了要监听的性能事件类型,这里监听了 "measure" 和 "paint" 两种类型的事件。
当指定的性能事件类型发生时,回调函数将被调用,并传递触发事件的 PerformanceEntry 对象作为参数。开发者可以在回调函数中进一步处理和分析这些对象,以获取性能数据并进行优化。
需要注意的是,观察者模式是异步的,因此回调函数可能不会立即执行。另外,一旦创建了 PerformanceObserver 实例,需要调用其 disconnect() 方法来停止监听性能事件,避免内存泄漏。
以上是 PerformanceObserver 的基本用法,开发者可以根据实际需求和业务场景来灵活运用。
PerformanceObserver 如何统计FP、FCP
要使用 PerformanceObserver 统计 FP(First Paint)和 FCP(First Contentful Paint),可以按照以下步骤进行:
- 创建 PerformanceObserver 实例,并指定一个回调函数作为参数。
const observer = new PerformanceObserver((list) => {
const entries = list.getEntries()
entries.forEach((entry) => {
if (entry.name === 'first-paint') {
console.log('FP:', entry.startTime)
} else if (entry.name === 'first-contentful-paint') {
console.log('FCP:', entry.startTime)
}
})
})
- 使用 PerformanceObserver 的 observe() 方法监听 'paint' 类型的性能事件。
observer.observe({ entryTypes: ['paint'] })
-
在回调函数中,通过遍历 PerformanceEntryList 对象的 getEntries() 方法获取所有触发的性能事件,然后根据 entry.name 来判断是否是 FP 或 FCP。
-
如果是 FP,可以通过 entry.startTime 获取其开始的时间戳,进行相应的处理。同样,如果是 FCP,也可以通过 entry.startTime 获取其开始的时间戳。
完整的示例代码如下:
const observer = new PerformanceObserver((list) => {
const entries = list.getEntries()
entries.forEach((entry) => {
if (entry.name === 'first-paint') {
console.log('FP:', entry.startTime)
} else if (entry.name === 'first-contentful-paint') {
console.log('FCP:', entry.startTime)
}
})
})
observer.observe({ entryTypes: ['paint'] })
在上述代码中,创建了一个 PerformanceObserver 实例,并指定一个回调函数。在回调函数中,根据 entry.name 的值判断是否是 FP 或 FCP,并打印出对应的开始时间戳。然后通过调用 observer.observe() 方法监听 'paint' 类型的性能事件。
通过以上步骤,就可以使用 PerformanceObserver 统计 FP 和 FCP,并对这些性能指标进行进一步的处理和分析。
PerformanceObserver 如何统计 long tasks
要使用 PerformanceObserver 统计长任务(Long Tasks),可以按照以下步骤进行:
- 创建 PerformanceObserver 实例,并指定一个回调函数作为参数。
const observer = new PerformanceObserver((list) => {
const entries = list.getEntries()
entries.forEach((entry) => {
console.log('Long Task:', entry)
})
})
- 使用 PerformanceObserver 的 observe() 方法监听 'longtask' 类型的性能事件。
observer.observe({ entryTypes: ['longtask'] })
-
在回调函数中,通过遍历 PerformanceEntryList 对象的 getEntries() 方法获取所有触发的长任务事件。
-
可以通过遍历获得的长任务事件数据,并进行进一步的处理和分析。
完整的示例代码如下:
const observer = new PerformanceObserver((list) => {
const entries = list.getEntries()
entries.forEach((entry) => {
console.log('Long Task:', entry)
})
})
observer.observe({ entryTypes: ['longtask'] })
在上述代码中,创建了一个 PerformanceObserver 实例,并指定一个回调函数。在回调函数中,遍历 PerformanceEntryList 对象的 getEntries() 方法获取所有长任务事件,并打印出相关的长任务数据。
通过以上步骤,就可以使用 PerformanceObserver 统计长任务,并对这些长任务进行进一步的处理和分析。
补充: 页面性能指标有哪些?
以下是常见的页面性能指标,按照阶段顺序进行表述:
| 阶段 | 指标名称 | 描述 |
|---|---|---|
| 导航阶段 | DNS 解析时间 | 浏览器解析域名并获取目标服务器IP地址所花费的时间 |
| 导航阶段 | TCP 连接时间 | 浏览器与服务器建立 TCP 连接所花费的时间 |
| 导航阶段 | SSL/TLS 握手时间 | 如果网站启用了 HTTPS,浏览器与服务器进行 SSL/TLS 握手所花费的时间 |
| 导航阶段 | 请求时间 | 浏览器发送 HTTP 请求并等待服务器响应的时间 |
| 导航阶段 | 首字节时间(TTFB) | 浏览器收到服务器响应的第一个字节所花费的时间 |
| 渲染阶段 | DOM 解析时间 | 浏览器将 HTML 文档解析为 DOM 树的时间 |
| 渲染阶段 | CSS 解析时间 | 浏览器将 CSS 样式表解析为 CSSOM 树的时间 |
| 渲染阶段 | 首次渲染时间(FP) | 浏览器将 DOM 树和 CSSOM 树合并,开始绘制页面的时间 |
| 渲染阶段 | 首次内容绘制时间(FCP) | 页面首次有可见内容被绘制的时间 |
| 渲染阶段 | 首次有意义绘制时间(FMP) | 页面首次有有意义的内容被绘制的时间 |
| 交互阶段 | 首次输入延迟时间(FID) | 用户首次与页面进行交互(点击按钮、输入框等)后,页面响应交互的时间 |
| 交互阶段 | 首次可交互时间(TTI) | 页面变得完全可交互(用户可以进行大部分常规操作)所花费的时间 |
| 交互阶段 | 页面完全加载时间(Page Load) | 页面所有资源(包括图片、CSS、JavaScript等)加载完成、渲染完毕并且可交互的时间 |
| 用户体验阶段 | 页面响应时间 | 用户发起请求后,页面完成响应所花费的时间 |
| 用户体验阶段 | 页面加载时间 | 用户打开页面到页面加载完成所花费的时间 |
| 用户体验阶段 | 页面交互性能 | 页面响应用户交互(点击、滚动等)的流畅程度 |
请注意,以上仅为常见的页面性能指标,并非所有指标都适用于每个网站。具体的指标选择取决于你的应用的特点和需求。
为什么传统上利用多个域名来提供网站资源会更有效?
采用什么工具查找性能问题?
参见 google 性能测量
如何改善网站滚动性能?
你如何对网站的文件和资源进行优化?
浏览器同一时间可以从一个域名下载多少资源,有什么例外吗?
总结
性能推荐看 google 性能教程 基于 RAIL 去分析性能.
性能优化的基本思路
- 加载性能 按照资源的类型处理
解释 layout,painting,compositing
css 动画和 js 动画优缺点?
请说出三种减少页面加载时间的方法
什么是 domain pre-fetching 它如何帮助性能?
说一下 Performance API
一、性能监测与优化
- 测量页面加载时间:
- 通过
performance.timing可以获取页面加载过程中的各个关键时间点,如navigationStart(导航开始时间)、domLoading(开始解析 DOM 的时间)、domInteractive(DOM 准备就绪时间)、domContentLoadedEventEnd(DOMContentLoaded事件结束时间)、loadEventEnd(页面完全加载时间)等。计算这些时间点之间的差值可以得出不同阶段的加载时间,帮助开发者了解页面加载的性能瓶颈并进行优化。 - 例如,可以计算从导航开始到页面完全加载的时间,以评估整体加载性能。
const timing = performance.timing
const loadTime = timing.loadEventEnd - timing.navigationStart
console.log(`Page load time: ${loadTime} milliseconds.`)
- 测量资源加载时间:
- 使用
performance.getEntriesByType('resource')可以获取所有资源(如脚本、样式表、图片等)的加载性能信息。可以分析每个资源的加载时间、发起请求的时间、响应时间等,以便优化资源的加载策略。 - 例如,可以找出加载时间较长的资源并考虑优化其大小、压缩方式或加载时机。
const resources = performance.getEntriesByType('resource')
for (const resource of resources) {
console.log(`Resource ${resource.name} took ${resource.responseEnd - resource.startTime} milliseconds to load.`)
}
- 监测网络请求耗时:
- 可以结合
fetch或XMLHttpRequest与 Performance API 来测量特定网络请求的耗时。在请求发送前记录时间戳,在请求完成后再次记录时间戳并计算差值,同时可以利用 Performance API 的其他信息来进一步分析请求性能。 - 例如,可以统计某个 API 请求的耗时并与其他指标一起分析网络性能对应用的影响。
const startTime = performance.now()
fetch('your-api-url')
.then((response) => {
const endTime = performance.now()
const duration = endTime - startTime
console.log(`API request took ${duration} milliseconds.`)
return response
})
.catch((error) => {
console.error(`Error fetching API: ${error}`)
})
二、用户体验优化
- 检测页面交互响应时间:
- 通过记录用户操作(如点击按钮、滚动页面等)的时间戳和相应的响应事件(如按钮点击后的处理完成时间、滚动事件触发后的页面更新时间等),可以测量用户交互的响应时间。这有助于确保应用在用户操作后能够及时做出反应,提高用户体验。
- 例如,可以在用户点击一个按钮后记录开始时间,在按钮对应的操作完成后记录结束时间,计算响应时间并进行优化。
document.getElementById('your-button').addEventListener('click', () => {
const startTime = performance.now()
// 执行按钮对应的操作
// ...
const endTime = performance.now()
const responseTime = endTime - startTime
console.log(`Button click response time: ${responseTime} milliseconds.`)
})
- 分析页面卡顿和流畅度:
- Performance API 中的
performance.now()可以提供高精度的时间戳,通过在一定时间间隔内记录时间戳并分析时间差,可以检测页面是否出现卡顿。如果连续的时间差较大,可能表示页面出现了卡顿现象。此外,还可以结合浏览器的requestAnimationFrame来确保动画和交互的流畅性,通过在每一帧中执行特定的操作并测量时间,可以判断页面的流畅度是否符合预期。 - 例如,可以在动画循环中记录每一帧的时间戳,分析帧与帧之间的时间间隔是否稳定,以检测动画的流畅度。
let lastFrameTime = performance.now()
function animate () {
const currentTime = performance.now()
const deltaTime = currentTime - lastFrameTime
if (deltaTime > 100) {
console.log('Possible卡顿 occurred.')
}
lastFrameTime = currentTime
requestAnimationFrame(animate)
}
requestAnimationFrame(animate)
三、性能分析工具开发
- 构建自定义性能分析工具:
- 利用 Performance API 提供的数据,可以开发自定义的性能分析工具,用于特定项目或团队的需求。这些工具可以收集和展示各种性能指标,提供详细的报告和分析,帮助开发者更好地理解应用的性能状况并进行针对性的优化。
- 例如,可以开发一个插件或工具,集成到开发环境中,实时监测页面性能并提供可视化的报告,包括加载时间、资源使用情况、网络请求耗时等。
class PerformanceAnalyzer {
constructor () {
this.measurements = []
}
startMeasurement () {
this.startTime = performance.now()
}
endMeasurement (label) {
const endTime = performance.now()
const duration = endTime - this.startTime
this.measurements.push({ label, duration })
}
generateReport () {
console.log('Performance Report:')
for (const measurement of this.measurements) {
console.log(`${measurement.label}: ${measurement.duration} milliseconds.`)
}
}
}
const analyzer = new PerformanceAnalyzer()
analyzer.startMeasurement()
// 执行一些操作
// ...
analyzer.endMeasurement('Operation 1')
analyzer.generateReport()
- 与其他性能工具集成:
- Performance API 的数据可以与其他性能分析工具(如 Lighthouse、WebPageTest 等)结合使用,提供更全面的性能分析。可以将 Performance API 收集的数据作为输入,与这些工具的报告进行对比和分析,以获得更深入的性能洞察。
- 例如,可以在使用 Lighthouse 进行性能测试的同时,利用 Performance API 记录特定操作的耗时,以便更细致地分析应用在不同方面的性能表现。
如何计算页面首屏时间
页面首屏时间是指从浏览器开始请求页面到页面的首屏内容完全显示的时间。以下是几种计算首屏时间的方法:
一、使用浏览器性能 API 和自定义事件
- 具体步骤:
- 在页面的
<head>标签中插入一段 JavaScript 代码,在页面加载时记录浏览器开始导航的时间戳,即performance.timing.navigationStart。 - 当页面的首屏内容加载完成时,触发一个自定义事件。可以通过监听特定元素的加载完成或者使用特定的标志来判断首屏内容是否加载完成。
- 在自定义事件的处理函数中,获取当前时间戳,并减去开始导航的时间戳,得到首屏时间。
例如:
<!DOCTYPE html>
<html>
<head>
<script>
const timing = performance.timing;
let firstScreenLoaded = false;
function onFirstScreenLoaded() {
if (!firstScreenLoaded) {
const firstScreenTime = performance.now() - timing.navigationStart;
console.log(`首屏时间为:${firstScreenTime}ms`);
firstScreenLoaded = true;
}
}
window.addEventListener("load", function () {
// 假设首屏内容加载完成的标志是某个特定元素的出现
const firstScreenElement = document.getElementById("first-screen-element");
if (firstScreenElement) {
onFirstScreenLoaded();
}
});
</script>
</head>
<body>
<!-- 页面内容 -->
<div id="first-screen-element">首屏关键内容元素</div>
</body>
</html>
- 注意事项:
- 需要准确确定首屏内容加载完成的标志,这可能因页面结构和内容而异。
- 不同浏览器对于性能时间戳的定义和准确性可能略有不同,需要在多种浏览器上进行测试。
二、使用可视化工具和浏览器插件
- 一些可视化性能分析工具,如 Lighthouse、WebPageTest 等,可以测量页面的首屏时间。
- Lighthouse 是一个由 Google 开发的开源工具,可以在 Chrome 浏览器的开发者工具中运行。它会生成一个详细的性能报告,其中包括首屏时间等指标。
- WebPageTest 是一个在线性能测试工具,可以从不同的地理位置和设备类型进行测试,并提供详细的性能数据,包括首屏时间。
-
一些浏览器插件,如 PageSpeed Insights、YSlow 等,也可以提供页面性能指标,包括首屏时间的估算。
-
注意事项:
- 这些工具和插件的测量结果可能会受到网络环境、测试设备等因素的影响。
- 需要结合实际情况进行分析和优化,不能完全依赖工具的测量结果。
三、手动计时和标记
- 步骤:
- 在页面的 JavaScript 代码中,在浏览器开始请求页面时手动记录一个时间戳。
- 在页面的首屏内容加载完成时,再次记录一个时间戳。
- 首屏时间 = 第二个时间戳 - 第一个时间戳。
例如:
<!DOCTYPE html>
<html>
<head>
<script>
let startTime;
window.addEventListener("load", function () {
if (!startTime) {
startTime = performance.now();
}
// 假设首屏内容加载完成的标志是某个特定元素的出现
const firstScreenElement = document.getElementById("first-screen-element");
if (firstScreenElement) {
const endTime = performance.now();
const firstScreenTime = endTime - startTime;
console.log(`首屏时间为:${firstScreenTime}ms`);
}
});
</script>
</head>
<body>
<!-- 页面内容 -->
<div id="first-screen-element">首屏关键内容元素</div>
</body>
</html>
- 注意事项:
- 这种方法需要手动在代码中插入计时逻辑,可能会比较繁琐。
- 同样需要准确确定首屏内容加载完成的标志。
如何计算页面白屏时间
白屏时间是指从浏览器开始请求页面到页面开始显示内容的时间。可以通过以下方法计算白屏时间:
一、使用浏览器的性能 API
现代浏览器提供了performance对象,可以用来获取页面加载过程中的各种时间戳。通过这些时间戳的差值可以计算出白屏时间。
- 具体步骤:
- 在页面的
<head>标签中插入一段 JavaScript 代码,在页面加载时记录关键时间点。 - 使用
performance.timing.navigationStart表示浏览器开始导航的时间戳。 - 寻找一个表示页面开始有内容显示的时间点,通常可以使用
performance.timing.domInteractive(文档被解析完成,开始加载外部资源时的时间戳)或者performance.timing.domContentLoadedEventStart(DOMContentLoaded事件开始的时间戳)作为近似的白屏结束时间点。 - 白屏时间 = 白屏结束时间点 -
performance.timing.navigationStart。
例如:
<!DOCTYPE html>
<html>
<head>
<script>
const timing = performance.timing;
const whiteScreenTime = timing.domInteractive - timing.navigationStart;
console.log(`白屏时间为:${whiteScreenTime}ms`);
</script>
</head>
<body>
<!-- 页面内容 -->
</body>
</html>
- 注意事项:
- 不同的浏览器对于性能时间戳的定义可能略有不同,需要在多种浏览器上进行测试以确保准确性。
- 这种方法计算的白屏时间是一个近似值,因为很难精确地确定页面开始显示内容的瞬间。
二、使用自定义标记和日志
- 步骤:
- 在页面的 HTML 结构中,在
<head>标签之后插入一个不可见的元素,例如一个空的<div>元素,并给它一个特定的 ID。 - 在页面的 CSS 中,将这个元素的背景颜色设置为与页面背景相同的颜色,使其在页面加载初期不可见。
- 在页面的 JavaScript 代码中,当页面开始有内容显示时,通过修改这个元素的样式使其变为可见,并记录当前时间。
- 白屏时间 = 元素变为可见的时间 - 浏览器开始导航的时间。
例如:
<!DOCTYPE html>
<html>
<head>
<style>
#whiteScreenMarker {
display: none;
}
</style>
<script>
const timing = performance.timing;
document.addEventListener("DOMContentLoaded", function () {
document.getElementById("whiteScreenMarker").style.display = "block";
const whiteScreenTime = performance.now() - timing.navigationStart;
console.log(`白屏时间为:${whiteScreenTime}ms`);
});
</script>
</head>
<body>
<div id="whiteScreenMarker"></div>
<!-- 页面内容 -->
</body>
</html>
- 注意事项:
- 这种方法需要手动在页面中插入标记元素和相应的 JavaScript 代码,可能会增加一些开发工作量。
- 同样需要考虑在不同浏览器上的兼容性和准确性。
有哪些前端性能分析工具
一、浏览器开发者工具
- Chrome DevTools:
- 功能强大,提供了丰富的性能分析选项。
- 在“Performance”(性能)面板中,可以录制页面的交互过程,分析 CPU 使用率、内存占用、网络请求等,找出性能瓶颈。
- “Network”(网络)面板可以查看请求的加载时间、大小等信息,帮助优化网络请求。
- “Lighthouse”功能可以对页面进行全面的性能、可访问性、最佳实践等方面的审计。
- Firefox Developer Tools:
- 类似 Chrome DevTools,具有性能分析、网络监测等功能。
- “Performance”工具可以分析页面加载和交互过程中的性能问题。
二、性能监测平台
- WebPageTest:
- 在线工具,可以从多个地点对网页进行性能测试。
- 提供详细的性能指标,如首次内容绘制(FCP)、最大内容绘制(LCP)、首次输入延迟(FID)等。
- 生成可视化的报告,帮助分析页面的加载过程和性能瓶颈。
- Pingdom Tools:
- 用于测试网站的性能和可用性。
- 提供页面加载时间、文件大小等信息,并给出优化建议。
三、前端性能监控工具
- Google Analytics:
- 虽然主要用于网站分析,但也可以提供一些性能相关的数据。
- 如页面加载时间、用户行为等,可以帮助了解用户体验和性能趋势。
- New Relic Browser:
- 提供全面的前端性能监控和分析。
- 可以实时监测页面性能,跟踪用户交互,提供详细的报告和警报。
四、代码分析工具
- Lighthouse CI:
- 可以集成到持续集成(CI)流程中,对代码进行自动化的性能审计。
- 确保代码在提交和部署前符合一定的性能标准。
- PageSpeed Insights API:
- 可以通过 API 方式获取页面的性能分析结果。
- 方便集成到自定义的工具或流程中,进行大规模的性能监测和优化。
动画性能如何检测
一、使用浏览器开发者工具
- Chrome 开发者工具:
- 打开 Chrome 浏览器,进入要检测动画性能的页面。
- 按下 F12 打开开发者工具,切换到“Performance”(性能)选项卡。
- 点击“Record”(录制)按钮开始录制页面的交互和动画。
- 进行页面上的动画操作,如滚动、拖动、动画播放等。
- 停止录制后,开发者工具会生成一个性能分析报告,其中包括 CPU 使用率、FPS(每秒帧数)、帧时间线等信息,可以帮助你分析动画的性能瓶颈。
二、使用 JavaScript 性能分析工具
Frame Timing API 可以用于检测动画性能。
2.1、Frame Timing API 的作用
Frame Timing API 提供了一种方式来测量浏览器渲染每一帧所花费的时间。这对于分析动画性能非常有用,因为它可以帮助你确定动画是否流畅,是否存在卡顿或掉帧的情况。
2.2、如何使用 Frame Timing API 进行性能检测
- 获取帧时间数据:
- 使用
performance.getEntriesByType('frame')方法可以获取帧时间数据的数组。每个条目代表一帧的信息,包括帧的开始时间、持续时间等。
const frameEntries = performance.getEntriesByType('frame')
frameEntries.forEach((entry) => {
console.log(`Frame start time: ${entry.startTime}`)
console.log(`Frame duration: ${entry.duration}`)
})
- 分析帧时间数据:
- 通过分析帧的持续时间,可以判断动画是否在预期的时间内渲染。如果帧的持续时间过长,可能表示动画出现了卡顿。
- 可以计算平均帧时间、最大帧时间等指标,以评估动画的整体性能。
- 结合其他性能指标:
- Frame Timing API 可以与其他性能指标一起使用,如 FPS(每秒帧数)、CPU 使用率等,以全面了解动画性能。
- 例如,可以使用
requestAnimationFrame来计算 FPS,并结合帧时间数据来确定动画的流畅度。
2.3、优势和局限性
- 优势:
- 提供精确的帧时间信息,有助于深入了解动画的性能细节。
- 可以在浏览器中直接使用,无需安装额外的工具。
- 局限性:
- 并非所有浏览器都完全支持 Frame Timing API,可能存在兼容性问题。
- 仅提供帧时间数据,对于复杂的动画性能问题,可能需要结合其他工具和技术进行分析。
三、使用在线性能检测工具
- WebPageTest:
- WebPageTest 是一个在线工具,可以对网页的性能进行全面的测试,包括加载时间、动画性能、资源加载等。
- 输入要测试的网页 URL,选择测试参数,如浏览器类型、地理位置等,然后启动测试。
- 测试完成后,会生成详细的报告,包括视频录制、性能指标图表等,可以帮助你分析动画性能问题。
- Lighthouse:
- Lighthouse 是一个由 Google 开发的开源工具,可以作为 Chrome 浏览器的扩展或命令行工具使用。
- 运行 Lighthouse 对网页进行审计,它会评估网页的性能、可访问性、最佳实践等方面,并提供详细的报告和建议。
- 在性能部分,会包括对动画性能的评估,如 FPS、主线程忙碌时间等指标。
需要详细记录多个操作链路的性能耗时,进行结构化场景分析,该如何做
操作节点指标
首先对一个操作链路切片:比如一个操作流程, 分拆为第一步, 第二步, 第三步....... 然后对每一步一个事件点。 然后统计每一个时间点之间的时间差, 就可以得出用户早操作每一步操作停留的时间。
甚至可以统计一个串行流程, 实际上是一样的。
阶段耗时统计
推荐: performance.mark()
performance.mark() 是 Web Performance API 的一部分,它允许你在浏览器的性能条目缓冲区中创建一个具有特定名称的时间戳(也就是一个"标记")。这些标记可用于精确测量页面或应用中的特定流程、操作、或某段代码的执行时间。通过使用performance.mark()来标记关键的代码执行点,你可以准确地测量出这些点之间的耗时,从而评估性能和识别瓶颈。
如何使用 performance.mark()
创建标记
要使用performance.mark(),直接调用此函数并传入一个字符串作为标记的名称即可:
performance.mark('startLoad')
// 执行一些操作
performance.mark('endLoad')
在上述示例中,startLoad和endLoad是两个标记点,分别表示加载操作的开始和结束。
测量两个标记间的耗时
创建标记后,你可以使用performance.measure()方法来测量这两个标记点之间的耗时。performance.measure()方法同样需要一个名称,并且可以接受两个额外的参数:起始标记和结束标记的名称。
performance.measure('loadDuration', 'startLoad', 'endLoad')
在上面的代码中,loadDuration是测量的名称,表示从startLoad到endLoad之间的耗时。
获取和分析测量结果
通过performance.getEntriesByName()或其他类似的 API,你可以获取到性能条目并分析结果:
const measure = performance.getEntriesByName('loadDuration')[0]
console.log(`加载耗时:${measure.duration}毫秒`)
performance.getEntriesByName('loadDuration')会返回一个数组,其中包含所有名为loadDuration的性能条目。在这个例子中,我们取数组的第一个元素,并通过duration属性获取实际的测量时间。
清理标记和测量
为了避免性能条目缓冲区满了或是数据混乱,你可以在完成测量和分析后,使用performance.clearMarks()和performance.clearMeasures()来清除标记和测量结果。
performance.clearMarks('startLoad')
performance.clearMarks('endLoad')
performance.clearMeasures('loadDuration')
使用场景
performance.mark()非常适合用于测量页面加载、脚本执行、用户交互处理或任何自定义流程的性能。通过准确地标记和测量这些操作的起始和结束时间,开发者可以识别出性能瓶颈和潜在的优化点,从而改进应用的性能表现。
注意事项
- 并非所有浏览器都支持 Web Performance API 的全部特性。使用这些 API 之前,建议检查兼容性。
- 对于高频率的性能标记和测量,要注意性能条目缓冲区可能会被快速填满,从而影响数据的收集和分析。确保适时清理不再需要的性能条目。
统计全站每一个静态资源加载耗时, 该如何做
要统计全站每一个静态资源(如图片、JS 脚本、CSS 样式表等)的加载耗时,你可以借助浏览器的 Performance API,特别是利用 PerformanceResourceTiming 接口来获取资源加载的详细时间信息。以下是一个基本的步骤指导和示例代码,展示如何实现这一功能:
步骤
-
使用
PerformanceObserver: 创建一个PerformanceObserver实例来监听资源加载事件,能够实时收集性能数据,而且对性能影响较小。 -
过滤静态资源类型: 通过检查
initiatorType属性,筛选出静态资源(例如img、script、css等)的加载事件。 -
计算和展示耗时: 对每个静态资源的加载耗时进行计算并展示。资源的耗时可以通过
duration属性直接获取。
示例代码
以下是一个简单的 JavaScript 代码示例,展示了如何使用 PerformanceObserver 来统计全站静态资源的加载耗时:
// 创建性能观察者实例来监听资源加载事件
const observer = new PerformanceObserver((list) => {
const entries = list.getEntries()
for (const entry of entries) {
// 过滤静态资源类型
if (['img', 'script', 'css', 'link'].includes(entry.initiatorType)) {
console.log(`资源 ${entry.name} 类型 ${entry.initiatorType} 耗时:${entry.duration.toFixed(2)} 毫秒`)
}
}
})
// 开始观察 Resource Timing 类型的性能条目
observer.observe({ entryTypes: ['resource'] })
注意事项
- 性能数据的准确性: 确保性能数据的准确性和实时性,你应该在页面加载的早期就开始监听资源加载事件,例如在
<head>标签中就引入或嵌入这段脚本。 - 跨域资源的时间信息: 如果你需要获取跨域资源的详细时间信息(如第三方字体或脚本),那么这些资源的服务器需要在响应头中包含
Timing-Allow-Origin头。 - 大量数据的处理: 如果页面包含大量静态资源,考虑如何存储、传输和分析这些数据,避免对性能和用户体验造成影响。
如何统计用户 pv 访问的发起请求数量(所有域名的)
统计用户 PV(页面访问量)期间发起的请求数量(涵盖所有域名)可以通过几种方法实现,包括使用浏览器的 Performance API、监听网络请求、或者通过服务端日志分析。每种方法有其优点和适用场景。下面是一些方法的简要说明和示例:
方法 1: 使用 Performance API
Performance API 提供了丰富的接口来访问和利用浏览器的性能数据。通过使用这个 API,可以获取到用户 PV 时所有资源请求的详细信息,包括请求的域名信息。
使用 PerformanceObserver 监听资源加载
const observer = new PerformanceObserver((list) => {
const entries = list.getEntriesByType('resource')
console.log(`当前页面共发起了 ${entries.length} 个资源请求。`)
})
observer.observe({ entryTypes: ['resource'] })
这段代码会统计所有类型的资源加载(如图片、脚本、样式表等),不过它不会区别处理各个域名的请求。
方法 2: 监听所有网络请求 (XMLHttpRequest 和 Fetch API)
可以通过重新定义 XMLHttpRequest 和拦截 fetch API 的调用来监控所有通过这两种常见方法发起的网络请求。
拦截 XMLHttpRequest
(function () {
const oldOpen = XMLHttpRequest.prototype.open
window.requestCount = 0
XMLHttpRequest.prototype.open = function () {
window.requestCount++
console.log(`请求数量: ${window.requestCount}`)
return oldOpen.apply(this, arguments)
}
})()
拦截 Fetch API
const oldFetch = window.fetch
window.fetch = function () {
window.requestCount++
console.log(`请求数量: ${window.requestCount}`)
return oldFetch.apply(this, arguments)
}
这两段代码分别拦截了 XMLHttpRequest 和 fetch API 的请求,从而可以统计请求的总量。为了覆盖所有域名,代码没有对请求的 URL 进行筛选,但如果需要,可以通过分析 URL 来对请求进行分类统计。
方法 3: 服务端日志分析
如果你有权访问服务器日志,或者使用了像 Google Analytics 这样的分析工具,也可以通过分析服务端日志来统计 PV 过程中的请求数量。这种方法可能更适合统计对外部 API 的请求或者整体网站流量的分析。
方法选择建议
- 如果你想要实时在前端捕获和反馈统计数据,建议使用
Performance API或者通过拦截网络请求的方法。 - 如果希望进行更全面的数据分析或长期趋势跟踪,服务端日志分析可能是更合适的选择。
可有办法判断用户的网络条件, 判断网速快慢,网络状态?
确定用户的网络条件,包括网络速度和连接状态,对于提供优质用户体验至关重要。以下是一些方法可以帮助你判断用户的网络条件:
- Navigator Connection API
这个 API 提供有关系统的网络连接的信息,如网络的类型和下载速度。这个 API 的支持度不是全局性的,但在许多现代浏览器上可用。使用这个 API,你可以获取到有关用户网络连接的详细信息。
if ('connection' in navigator) {
const connection = navigator.connection || navigator.mozConnection || navigator.webkitConnection
console.log(`网络类型: ${connection.effectiveType}`)
console.log(`估计的下行速度: ${connection.downlink}Mbps`)
console.log(`RTT: ${connection.rtt}ms`)
// 监听网络类型变化
connection.addEventListener('change', (e) => {
console.log(`网络类型变化为: ${connection.effectiveType}`)
})
}
connection.effectiveType提供了网络的类型,如'4g','3g',代表网络速度。connection.downlink提供了网络的下载速度信息,单位是 Mbps。connection.rtt提供了来回时间信息,单位是毫秒。
- 观测发送请求的速度
通过发送一个小请求(可能是一个小文件或 API 请求)并测量它完成的时间,可以粗略地估计当前的网络速度。
const startTime = new Date().getTime() // 记录开始时间
fetch('your-small-file-or-api-url').then((response) => {
const endTime = new Date().getTime() // 记录结束时间
const duration = endTime - startTime // 请求持续时间
console.log(`请求持续时间: ${duration}ms`)
// 根据持续时间和文件大小估计网速
})
- 监听在线和离线事件
HTML5 引入了在线和离线事件监听,可以用来简单判断用户是否连接到网络。
window.addEventListener('online', () => console.log('网络已连接'))
window.addEventListener('offline', () => console.log('网络已断开'))
根据navigator.onLine的属性值,你可以检测用户是否在线。
if (navigator.onLine) {
console.log('用户在线')
} else {
console.log('用户离线')
}
结论
虽然无法精确地测量用户的网速,但以上方法提供了一些手段来估计用户的网络状况。这样的信息可以用来动态调整网站或应用的行为,例如,通过降低图像质量、推迟非关键资源的加载或取消某些动画,以改善慢速连接下的用户体验。
PerformanceObserver 如何测量页面性能
PerformanceObserver API 是一个强大的浏览器接口,允许开发者订阅性能相关的事件,实时收集和分析用户当前浏览器会话中的性能数据。这个 API 是 Web 性能监测工具箱的一部分,与 window.performance 对象紧密协作,后者提供了对网页性能数据的访问。PerformanceObserver 允许应用异步监听性能测量事件,而不需要定时检查 window.performance 的条目。
核心功能
- 实时性能数据收集:随着网页生命周期中各种事件的触发,
PerformanceObserver支持实时捕获和处理性能数据条目。 - 减少资源消耗:与轮询
window.performance对象相比,使用PerformanceObserver可以降低资源消耗,并提供更及时的数据收集。 - 灵活的数据订阅模型:可以指定订阅一个或多个特定类型的性能条目,根据需要接收相关数据。
主要方法
observe():开始观察一个或多个特定类型的性能条目。通过指定条目类型,应用可以订阅感兴趣的性能事件。disconnect():停止观察性能数据。这可以释放相关资源,并停止进一步的回调执行。
使用示例
下面的例子展示了如何使用 PerformanceObserver 来监听首次内容绘制 (First Contentful Paint, FCP) 和最大内容绘制 (Largest Contentful Paint, LCP) 的性能指标。
const perfObserver = new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
if (entry.name === 'first-contentful-paint') {
console.log('FCP:', entry.startTime)
} else if (entry.name === 'largest-contentful-paint') {
console.log('LCP:', entry.startTime)
}
}
})
perfObserver.observe({ type: 'paint', buffered: true })
在这个例子中,perfObserver 被配置为监听包含 FCP 和 LCP 的 paint 类型的性能条目。当这些指标被记录到性能时间线上时,回调函数将被执行,并可以对这些数据进行进一步的处理,比如打印在控制台或发送到服务器。
注意事项
PerformanceObserverAPI 的支持程度取决于浏览器和浏览器版本。为了最好地利用这一 API,推荐检查目标用户群体最常用浏览器的兼容性。- 合理使用
disconnect()方法来停止数据的观察(特别是在单页应用中或在不再需要收集数据时)有助于保持应用的性能。 buffered选项允许接收到观察者激活之前已经记录的性能条目,这在页面加载阶段尤其有用。
通过 PerformanceObserver,开发者可以精细控制性能数据的收集过程,有效监控和分析网页性能,从而提升用户体验。
如何统计页面的 long task
主线程一次只能处理一个任务(任务按照队列执行)。当任务超过某个确定的点时,准确的说是50毫秒,就会被称为长任务(Long Task)。当长任务在执行时,如果用户想要尝试与页面交互或者一个重要的渲染更新需要重新发生,那么浏览器会等到Long Task执行完之后,才会处理它们。结果就会导致交互和渲染的延迟
所以从以上信息可以得知,如果存在Long Task,那么对于我们Load(加载时)和Runtime(运行时)的性能都有影响
阻塞主线程达 50 毫秒或以上的任务会导致以下问题:
- 可交互时间 延迟
- 严重不稳定的交互行为 (轻击、单击、滚动、滚轮等) 延迟(High/variable input latency)
- 严重不稳定的事件回调延迟(High/variable event handling latency)
- 紊乱的动画和滚动(Janky animations and scrolling)
任何连续不间断的且主 UI 线程繁忙 50 毫秒及以上的时间区间。比如以下常规场景:
- 长耗时的事件回调(long running event handlers)
- 代价高昂的回流和其他重绘(expensive reflows and other re-renders)
- 浏览器在超过 50 毫秒的事件循环的相邻循环之间所做的工作(work the browser does between different turns of the event loop that exceeds 50 ms)
任务管理策略
软件架构中有时候会将一个任务拆分成多个函数,这不仅能增强代码可读性,也让项目更容易维护,当然这样也更容易写测试。
function saveSettings () {
validateForm()
showSpinner()
saveToDatabase()
updateUI()
sendAnalytics()
}
在上面的例子中,该函数saveSettings调用了另外5个函数,包括验证表单、展示加载的动画、发送数据到后端等。理论上讲,这是很合理的架构。如果需调试这些功能,也只需要在项目中查找每个函数即可。 然而,这样也有问题,就是js并不是为每个方法开辟一个单独的任务,因为这些方法都包含在saveSetting这个函数中,也就是说这五个方法在一个任务中执行 saveSetting这个函数调用5个函数,这个函数的执行看起来就像一个特别长的长的任务。
如何解决 Long Tasks
那解决Long Task的方式有如下几种:
- 使用setTimeout分割任务
- 使用async/await分割任务
- isInputPending
- 专门编排优先级的api: Scheduler.postTask()
- 使用 web worker,处理逻辑复杂的计算
SetTimeout
setTimeout本身就是个Task。假如我们给某个函数加上setTimeout,是不是就可以将某个任务分离出去,成为单独的Task了。 延迟了回调的执行,而且使用该方法,即便是将delay时间设定成0,也是有效的。
function saveSettings () {
// Do critical work that is user-visible:
validateForm()
showSpinner()
updateUI()
// Defer work that isn't user-visible to a separate task:
setTimeout(() => {
saveToDatabase()
sendAnalytics()
}, 0)
}
并不是所有场景都能使用这个方法。比如,如需要在循环中处理大数据量的数据,这个任务的耗时可能就会非常长(假设有数百万的数据量)
使用async、await来创造让步点
分解任务后,按照浏览器内部的优先级别划分,其他的任务可能优先级别调整的会更高。一种让步于主线程的方式是配合用了setTimeout的promise。
function yieldToMain () {
return new Promise(resolve => {
setTimeout(resolve, 0)
})
}
在saveSettings的函数中,可以在每次await函数yieldToMain后让步于主线程:
async function saveSettings () {
// Create an array of functions to run:
const tasks = [validateForm, showSpinner, saveToDatabase, updateUI, sendAnalytics]
// Loop over the tasks:
while (tasks.length > 0) {
// Shift the first task off the tasks array:
const task = tasks.shift()
// Run the task:
task()
// Yield to the main thread:
await yieldToMain()
}
}
isInputPending
假如有一堆的任务,但是只想在用户交互的时候才让步,该怎么办?正好有这种api--isInputPending
isInputPending这个函数可以在任何时候调用,它能判断用户是否要与页面元素进行交互。调用isInputPending会返回布尔值,true代表要与页面元素交互,false则不交互。
比如说,任务队列中有很多任务,但是不想阻挡用户输入,使用isInputPending和自定义方法yieldToMain方法,就能够保证用户交互时的input不会延迟。
async function saveSettings () {
// 函数队列
const tasks = [validateForm, showSpinner, saveToDatabase, updateUI, sendAnalytics]
while (tasks.length > 0) {
// 让步于用户输入
if (navigator.scheduling.isInputPending()) {
// 如果有用户输入在等待,则让步
await yieldToMain()
} else {
// Shift the the task out of the queue:
const task = tasks.shift()
// Run the task:
task()
}
}
}
使用isInputPending配合让步的策略,能让浏览器有机会响应用户的重要交互,这在很多情况下,尤其是很多执行很多任务时,能够提高页面对用户的响应能力。
另一种使用isInputPending的方式,特别是担心浏览器不支持该策略,就可以使用另一种结合时间的方式。
async function saveSettings () {
// A task queue of functions
const tasks = [validateForm, showSpinner, saveToDatabase, updateUI, sendAnalytics]
let deadline = performance.now() + 50
while (tasks.length > 0) {
// Optional chaining operator used here helps to avoid
// errors in browsers that don't support `isInputPending`:
if (navigator.scheduling?.isInputPending() || performance.now() >= deadline) {
// There's a pending user input, or the
// deadline has been reached. Yield here:
await yieldToMain()
// Extend the deadline:
deadline += 50
// Stop the execution of the current loop and
// move onto the next iteration:
continue
}
// Shift the the task out of the queue:
const task = tasks.shift()
// Run the task:
task()
}
}
专门编排优先级的api: Scheduler.postTask()
可以参考文档: 资料
postTask允许更细粒度的编排任务,该方法能让浏览器编排任务的优先级,以便地优先级别的任务能够让步于主线程。目前postTask使用promise,接受优先级这个参数设定。
postTask方法有三个优先级别:
background级,适用于优先级别最低的任务user-visible级,适用于优先级别中等的任务,如果没有入参,也是该函数的默认参数。user-blocking级,适用于优先级别最高的任务。
拿下面的代码来举例,postTask在三处分别都是最高优先级别,其他的另外两个任务优先级别都是最低。
function saveSettings () {
// Validate the form at high priority
scheduler.postTask(validateForm, { priority: 'user-blocking' })
// Show the spinner at high priority:
scheduler.postTask(showSpinner, { priority: 'user-blocking' })
// Update the database in the background:
scheduler.postTask(saveToDatabase, { priority: 'background' })
// Update the user interface at high priority:
scheduler.postTask(updateUI, { priority: 'user-blocking' })
// Send analytics data in the background:
scheduler.postTask(sendAnalytics, { priority: 'background' })
}
在上面例子中,通过这些任务的优先级的编排方式,能让高浏览器级别的任务,比如用户交互等得以触发。
提醒: postTask 并不是所有浏览器都支持。可以检测是否空,或者考虑使用polyfill。
web worker
web worker是运行在Main线程之外的一个线程,叫做worker线程。我们可以把一些计算量大的任务放到worker中去处理
主线程上的所有Long Task都消失了,复杂的计算都到单独的worker线程去处理了。但是workder线程仍然存在Long Task,不过没有关系,只要主线程没有Long Task,那就不影响构建、渲染了。
参考文档
统计网页中的 LongTask 是性能监控的一部分,特别是在测量和优化页面的响应能力方面非常有用。LongTask API 提供了一种监测浏览器主线程被长时间任务阻塞的能力,这些任务通常会影响用户体验,如使滚动卡顿或延迟输入响应。下面是一些基本步骤,帮助你开始监控 LongTask:
-
使用 Performance Observer API: 这个 API 允许你注册一个观察者来获取性能相关的数据,包括
LongTask。 -
注册 LongTask 观察者:
- 创建一个
PerformanceObserver实例,并为其提供一个回调函数。这个回调函数会在观察到LongTask时被调用。 - 在回调函数中,你可以获取到每个
LongTask的详细信息,如开始时间、持续时间等。 - 调用
observe()方法开始观察性能条目,指定{entryTypes: ['longtask']}来仅观察LongTask。
- 处理 LongTask 数据:
- 在上述回调中,你可以收集
LongTask的数据并进行处理,例如计算平均持续时间,或将数据发送到服务器进行进一步分析。
下面是一个简单的示例代码,演示如何注册 LongTask 观察者并打印任务的一些基本信息:
const observer = new PerformanceObserver((list) => {
list.getEntries().forEach((entry) => {
console.log('LongTask Detected:', entry)
console.log(`Start Time: ${entry.startTime}, Duration: ${entry.duration}`)
// TODO: 这里可以根据需要进一步处理这些数据,比如发送给服务器
})
})
// 开始观察长任务
observer.observe({ entryTypes: ['longtask'] })
- 优化相关代码:
- 一旦你开始收集到
LongTask数据,可以识别出影响性能的代码区域,并进行相应的优化。
- 监控页面性能:
- 持续监控并优化,根据收集到的数据调整策略。
记住,只有支持 Performance Timeline Level 2 规范的浏览器才能使用 LongTask API。在实际部署之前,确保你有对应的浏览器兼容性检查和错误处理代码。
在 JavaScript 中,可以使用 Performance API 中的 PerformanceObserver 来监视和统计长任务(Long Task)。长任务是指那些执行时间超过 50 毫秒的任务,这些任务可能会阻塞主线程,影响页面的交互性和流畅性。
使用 PerformanceObserver 监听长任务
// 创建一个性能观察者实例来订阅长任务
let observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log('Long Task detected:')
console.log(`Task Start Time: ${entry.startTime}, Duration: ${entry.duration}`)
}
})
// 开始观察长任务
observer.observe({ entryTypes: ['longtask'] })
// 启动长任务统计数据的变量
let longTaskCount = 0
let totalLongTaskTime = 0
// 更新之前的性能观察者实例,以增加统计逻辑
observer = new PerformanceObserver((list) => {
list.getEntries().forEach((entry) => {
longTaskCount++ // 统计长任务次数
totalLongTaskTime += entry.duration // 累加长任务总耗时
// 可以在这里添加其他逻辑,比如记录长任务发生的具体时间等
})
})
// 再次开始观察长任务
observer.observe({ entryTypes: ['longtask'] })
在上面的代码中,我们创建了一个PerformanceObserver对象来订阅长任务。每当检测到长任务时,它会向回调函数传递一个包含长任务性能条目的列表。在这个回调中,我们可以统计长任务的次数和总耗时。
注意:PerformanceObserver需要在支持该 API 的浏览器中运行。截至到我所知道的信息(2023 年 4 月的知识截点),所有现代浏览器都支持这一 API,但在使用前你应该检查用户的浏览器是否支持这个特性。
以下是如何在实际使用中停止观察和获取当前的统计数据:
// 停止观察能力
observer.disconnect()
// 统计数据输出
console.log(`Total number of long tasks: ${longTaskCount}`)
console.log(`Total duration of all long tasks: ${totalLongTaskTime}ms`)
使用这种方法,你可以监控应用程序中的性能问题,并根据长任务的发生频率和持续时间进行优化。
浏览器对队头阻塞有什么优化?
队头阻塞(Head-of-Line Blocking,缩写 HoLB)问题主要发生在网络通信中,特别是在使用 HTTP/1.1 和以前版本时,在一个 TCP 连接中同一时间只能处理一个请求。即使后续的请求已经准备好在客户端,它们也必须等待当前处理中的请求完成后才能被发送。这会延迟整个页面或应用的网络请求,降低性能。
现代浏览器和协议已经实施了多种优化措施来减少或解决队头阻塞问题:
-
HTTP/2: 为了解决 HTTP/1.x 的诸多问题,包括队头阻塞问题,HTTP/2 引入了多路复用(multiplexing)功能。这允许在同一 TCP 连接上同时传输多个独立的请求-响应消息。与 HTTP/1.1 相比,HTTP/2 在同一个连接上可以并行处理多个请求,大大减少了队头阻塞的问题。
-
服务器推送: HTTP/2 还引入了服务器推送(server push)功能,允许服务器主动发送多个响应到客户端,而不需要客户端明确地为每个资源提出请求。这提高了页面加载的速度,因为相关资源可以被预先发送而无需等待浏览器请求。
-
域名分散(Domain Sharding): 这种技术常用于 HTTP/1.1 中,通过创建多个子域,使得浏览器可以同时开启更多的 TCP 连接来加载资源。虽然这种方法可以在一定程度上减轻队头阻塞,但它增加了复杂性,并且在 HTTP/2 中由于多路复用功能变得不再必要。
-
连接重用(Connection Reuse): 这是 HTTP/1.1 中的一个特性,即持久连接(Persistent Connections),允许在一次 TCP 连接中发送和接收多个 HTTP 请求和响应,而无需开启新的连接,从而减少了 TCP 握手的开销并提升了效率。
-
资源优化: 减少资源的大小通过压缩(如 GZIP),优化图片,减少 CSS 和 JavaScript 文件的大小等,可以减少队头阻塞的影响,因为小资源文件传输更快。
-
优先级设置: HTTP/2 允许设置资源的加载优先级,使得关键资源(如 HTML,CSS,JavaScript)可以比不那么重要的资源(如图片,广告)更早加载。
-
预加载: 浏览器可以通过使用
<link rel="preload">标签预加载关键资源,例如字体文件和关键脚本,这样可以确保它们在主要内容加载之前已经准备好。 -
HTTP/3 和 QUIC 协议: HTTP/3 是未来的推进方向,它基于 QUIC 协议,一个在 UDP 之上的新传输层协议,旨在进一步减少延迟,解决 TCP/IP 协议的队头阻塞问题。
总的来说,HTTP/2 的特性如多路复用、服务器推送和优先级设置都有助于减少队头阻塞。而 HTTP/3 的引入可能会在未来为网络通信带来根本性的变化。在使用 HTTP/2、HTTP/3 和浏览器级别的优化时,网页开发者也需注意资源加载优化的最佳实践,以更全面地应对队头阻塞问题。
图片进行优化?
图片作为网页和移动应用中不可或缺的元素之一,对于用户体验和网站性能都有着重要的影响。
加载速度是用户体验的关键因素之一,而大尺寸的图片会增加网页加载时间,导致用户等待时间过长,从而影响用户的满意度和留存率。通过优化图片,我们可以显著减少页面加载时间,提供更快速流畅的使用体验。
图片优化是提升用户体验、提高网站性能、减少流量消耗和增加搜索引擎曝光度的关键因素。为了提供更出色的用户体验,同时也提升网站的性能。总结了一下通用的图片优化首手段。
- 选择合适的图片格式
以下是对常用的图片格式jpg、png和webp进行深度对比的表格:
| 特性 | JPG | PNG | WebP |
|---|---|---|---|
| 压缩算法 | 有损压缩 | 无损压缩 | 有损压缩 |
| 透明度 | 不支持透明度 | 支持透明度 | 支持透明度 |
| 图片质量 | 可调整质量 | 无法调整质量 | 可调整质量 |
| 文件大小 | 相对较小 | 相对较大 | 相对较小 |
| 浏览器支持 | 支持在所有主流浏览器上显示 | 支持在所有主流浏览器上显示 | 部分浏览器支持 |
| 动画支持 | 不支持动画 | 不支持动画 | 支持动画 |
| 兼容性 | 兼容性较好 | 兼容性较好 | 兼容性较差 |
请注意,这个表格只是对这些格式的一般特征进行了总结,并不代表所有情况。实际情况可能因图像内容、压缩设置和浏览器支持等因素而有所不同。因此,在选择图像格式时,您应根据具体要求和应用场景进行评估和选择。
- 图片压缩
主要介绍 webpack 对图片进行压缩,可以使用以下步骤:
- 安装依赖:首先,确保你已经在项目中安装了webpack和相关的loader。可以使用以下命令安装所需的loader:
npm install --save-dev file-loader image-webpack-loader
- 配置Webpack:在Webpack的配置文件中进行相关配置。以下是一个简单的示例:
const path = require('path')
module.exports = {
entry: 'src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist')
},
module: {
rules: [
{
test: /\.(png|jpe?g|gif)$/i,
use: [
{
loader: 'file-loader',
options: {
name: '[name].[ext]',
outputPath: 'images/'
}
},
{
loader: 'image-webpack-loader',
options: {
mozjpeg: {
progressive: true,
quality: 65
},
// optipng.enabled: false will disable optipng
optipng: {
enabled: false
},
pngquant: {
quality: [0.65, 0.90],
speed: 4
},
gifsicle: {
interlaced: false
},
// the webp option will enable WEBP
webp: {
quality: 75
}
}
}
]
}
]
}
}
上述配置中,我们使用file-loader将图片复制到输出目录,并使用image-webpack-loader对图片进行压缩和优化。
-
运行Webpack:现在,当你运行Webpack时,它将自动使用
image-webpack-loader对匹配到的图片进行压缩和优化。压缩后的图片将被复制到输出目录中。 -
雪碧图
Web图片优化的雪碧图(CSS Sprites)是一种将多个小图片合并为一个大图片的技术。通过将多个小图片合并成一张大图片,可以减少浏览器发送的请求次数,从而提高页面加载速度。
雪碧图的原理是通过CSS的background-image和background-position属性,将所需的小图片显示在指定的位置上。这样,只需加载一张大图,就可以显示多个小图片,减少了网络请求的数量,提高了页面加载速度。
听上去好像很麻烦, 实际上可以使用 webpack 插件 webpack-spritesmith 完成自动化处理雪碧图合成,我们在使用过程中正常使用即可。
以下是使用webpack-spritesmith插件来自动处理雪碧图的步骤:
- 安装插件:使用npm或yarn安装
webpack-spritesmith插件。
npm install webpack-spritesmith --save-dev
- 配置Webpack:在Webpack配置文件中,引入
webpack-spritesmith插件,并配置相应的选项。
const SpritesmithPlugin = require('webpack-spritesmith')
module.exports = {
// ...其他配置
plugins: [
new SpritesmithPlugin({
src: {
cwd: path.resolve(__dirname, 'path/to/sprites'), // 需要合并的小图片所在的目录
glob: '*.png' // 小图片的文件名格式
},
target: {
image: path.resolve(__dirname, 'path/to/output/sprite.png'), // 生成的雪碧图的路径和文件名
css: path.resolve(__dirname, 'path/to/output/sprite.css') // 生成的CSS样式表的路径和文件名
},
apiOptions: {
cssImageRef: 'path/to/output/sprite.png' // CSS样式表中引用雪碧图的路径
}
})
]
}
- 使用雪碧图:在HTML中,使用生成的CSS样式类来显示相应的小图片。Webpack会自动处理雪碧图的合并和CSS样式的生成。例如:
然后,你可以按照以下方法在CSS中引用雪碧图:
CSS方式:
<div {
background: url(path/to/output/sprite.png) no-repeat;
}
.icon-facebook {
// 设置小图标在雪碧图中的位置和大小 */
width: 32px;
height: 32px;
background-position: 0 0; // 该小图标在雪碧图中的位置 */
}
.icon-twitter {
width: 32px;
height: 32px;
background-position: -32px 0; // 该小图标在雪碧图中的位置 */
}
.icon-instagram {
width: 32px;
height: 32px;
background-position: -64px 0; // 该小图标在雪碧图中的位置 */
}
在HTML中,你可以像下面这样使用对应的CSS类来显示相应的小图标:
<div class="icon icon-facebook"></div>
<div class="icon icon-twitter"></div>
<div class="icon icon-instagram"></div>
这样,Webpack会根据配置自动处理雪碧图,并生成对应的雪碧图和CSS样式表。CSS中的background属性会引用生成的雪碧图,并通过background-position来指定显示的小图标在雪碧图中的位置。
确保在CSS中指定了每个小图标在雪碧图中的位置和大小,以便正确显示。
使用Webpack自动处理雪碧图可以简化开发流程,并且可以根据需要自定义配置。webpack-spritesmith是一个常用的Webpack插件,可以帮助自动处理雪碧图。
- 图标类型资源推荐使用 iconfont
如果你有很多图标类型的图片资源,并且想使用iconfont来处理这些资源,可以按照以下步骤进行处理:
-
获取图标资源:首先,你需要获取你想要的图标资源。你可以从
iconfont网站或其他图标库中选择和下载符合需求的图标。这个没有啥好说的, 直接推荐: 资料 -
生成字体文件:接下来,你需要将这些图标转换成字体文件。你可以使用
iconfont提供的在线转换工具,将图标文件上传并生成字体文件(包括.ttf、.eot、.woff和.svg格式)。 -
引入字体文件:将生成的字体文件下载到本地,并在你的项目中引入。通常,你需要在CSS文件中通过
@font-face规则引入字体文件,并为字体定义一个唯一的名称。 -
使用图标:一旦字体文件引入成功,你可以在CSS中通过设置
content属性来使用图标。每个图标都会有一个对应的Unicode代码,你可以在iconfont提供的网站或字体文件中找到对应图标的Unicode代码,并通过设置content属性的值为该Unicode代码来使用图标。
以下是一个简单的示例,以帮助你更好地理解:
@font-face {
font-family: 'iconfont';
src: url('path/to/iconfont.eot'); // 引入字体文件 */
// 其他格式的字体文件 */
}
.icon {
font-family: 'iconfont'; // 使用定义的字体名称 */
font-size: 16px; // 图标大小 */
line-height: 1; // 图标行高 */
}
.icon-facebook::before {
content: '\e001'; // 使用Unicode代码表示想要显示的图标 */
}
.icon-twitter::before {
content: '\e002'; // 使用Unicode代码表示想要显示的图标 */
}
.icon-instagram::before {
content: '\e003'; // 使用Unicode代码表示想要显示的图标 */
}
在上述示例中,我们首先通过@font-face引入了字体文件,并为字体定义了一个名称iconfont。然后,我们使用该名称作为font-family属性的值,以便在.icon类中使用该字体。最后,我们通过在::before伪元素中设置content属性为图标的Unicode代码,来显示相应的图标。
在HTML中,你可以像下面这样使用对应的CSS类来显示相应的图标:
<span class="icon icon-facebook"></span>
<span class="icon icon-twitter"></span>
<span class="icon icon-instagram"></span>
通过上述步骤,你可以使用iconfont来处理你的图标资源,并在项目中方便地使用它们。确保在CSS中设置了图标的字体大小和行高,以便正确显示图标。
- 使用 base64 格式
实际开发过程中, 为何会考虑 base64 ?
使用Base64图片的优势有以下几点:
-
减少HTTP请求数量:通常情况下,每个网页都需要加载多张图片,因此会发送多个HTTP请求来获取这些图片文件。使用Base64图片可以将图片数据嵌入到CSS或HTML文件中,减少了对服务器的请求次数,从而提高网页加载速度。
-
减少图片文件的大小:Base64是一种编码方式,可以将二进制数据转换成文本字符串。通过使用Base64,可以将图片文件转换成文本字符串,并将其嵌入到CSS或HTML文件中。相比于直接引用图片文件,Base64编码的字符串通常会更小,因此可以减少图片文件的大小,从而减少了网页的总体积,加快了网页加载速度。
-
简化部署和维护:将图片数据嵌入到CSS或HTML文件中,可以减少文件的数量和复杂性,使得部署和维护变得更加简单和方便。此外,也不需要处理图片文件的路径和引用相关的问题。
-
实现一些特殊效果:通过Base64图片,可以实现一些特殊的效果,例如页面背景渐变、图标的使用等。这样可以避免使用额外的图片文件,简化了开发过程。
上面虽然说饿了挺多有点, 但是劣势也是很明显:
-
增加了文本文件的体积:因为Base64编码将二进制数据转换成文本字符串,所以会增加CSS或HTML文件的体积。在图片较大或数量较多时,这可能会导致文件变得庞大,从而导致网页加载速度变慢。
-
缓存问题:由于Base64图片被嵌入到了CSS或HTML文件中,如果图片内容有更新,那么整个文件都需要重新加载,而无法使用缓存。相比于独立的图片文件,Base64图片对缓存的利用效率较低。
使用Base64图片在一些特定的场景下可以提供一些优势,但也需要权衡其带来的一些缺点。在实际开发中,可以根据具体的需求和情况,选择是否使用Base64图片。 所以建议复用性很强, 变更率较低, 且 小于 10KB 的图片文件, 可以考虑 base64
如何使用? 有要介绍一下 webpack 插件了: url-loader 或 file-loader
要使用Webpack将图片自动转换为Base64编码,您需要执行以下步骤:
- 安装依赖:首先,确保您已经安装了
url-loader或file-loader,它们是Webpack的两个常用的加载器。
npm install url-loader --save-dev
- 配置Webpack:在Webpack的配置文件中,添加对图片文件的处理规则。您可以在
module.rules数组中添加一个新的规则,以匹配图片文件的后缀。
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.(png|jpe?g|gif)$/i,
use: [
{
loader: 'url-loader',
options: {
limit: 8192, // 设置图片大小的阈值,小于该值的图片会被转为Base64
outputPath: 'images', // 输出路径
publicPath: 'images' // 资源路径
}
}
]
}
]
}
// ...
}
在上面的示例中,配置了一个处理png、jpeg、jpg和gif格式图片的规则。使用url-loader加载器,并设置了一些选项,例如limit限制了图片大小的阈值,小于该值的图片将会被转换为Base64编码。
- 在代码中引用图片:在您的代码中,可以像引用普通图片一样引用图片文件,Webpack会根据配置自动将其转换为Base64编码。
import imgSrc from './path/to/image.png'
const imgElement = document.createElement('img')
imgElement.src = imgSrc
document.body.appendChild(imgElement)
- 构建项目:最后,使用Webpack构建项目,它会根据配置自动将符合规则的图片文件转换为Base64编码,并将其嵌入到生成的输出文件中。
npx webpack
这样,Webpack就会自动将图片转换为Base64编码,并将其嵌入到生成的输出文件中。请注意,在使用Base64图片时,需要权衡文件大小和性能,适度使用Base64编码,避免过大的文件导致网页加载变慢。
- 使用 CDN 加载图片
CND 加载图片优势非常明显:
-
加速网页加载速度:CDN通过将图片资源分布在全球的多个节点上,使用户能从离自己最近的节点获取资源,从而大大减少了网络延迟和加载时间。这可以提高网页的加载速度和用户体验。
-
减轻服务器负载:CDN充当了一个缓冲层,当用户请求图片资源时,CDN会将图片资源从源服务器获取并缓存在节点中,下次再有用户请求同一资源时,CDN会直接从节点返回,减少了对源服务器的请求,分担了服务器的负载。
-
提高并发性能:CDN节点分布在不同地区,用户请求图片资源时可以从离他们最近的节点获取,这可以减少网络拥塞和并发请求,提高了并发性能。
-
节省带宽成本:CDN的节点之间会自动选择最优路径,有效利用了带宽资源,减少了数据传输的成本,尤其在大量图片资源请求时,能够带来显著的成本节省。
-
提供高可用性:CDN通过分布式存储和负载均衡技术,提供了高可用性和容错能力。即使某个节点或源服务器发生故障,CDN会自动切换到其他可用节点,确保用户能够正常访问图片资源。
总之,使用CDN加载图片可以提高网页加载速度、降低服务器负载、提高并发性能、节省带宽成本,并提供高可用性,从而改善用户体验和网站性能。
- 图片懒加载
图片懒加载是一种在网站或应用中延迟加载图片的技术。它的主要目的是减少页面的初始加载时间,并提高用户的浏览体验。
-
原理:图片懒加载的原理是只在用户需要时加载图片,而不是在页面初始加载时全部加载。这通常通过将图片的真实地址存储在自定义属性(例如
data-src)中,而不是在src属性中。然后,在图片进入浏览器视图时,通过JavaScript动态将data-src的值赋给src属性,触发图片的加载。 -
优势:图片懒加载可以显著减少初始页面的加载时间,特别是当页面中有大量图片时。它使页面加载变得更快,提高了用户的浏览体验。此外,懒加载还可以节省带宽和减轻服务器负载,因为只有当图片进入视图时才会加载。
-
实现方法:图片懒加载可以通过纯JavaScript实现,也可以使用现成的JavaScript库,如
LazyLoad.js、Intersection Observer API等。这些库提供了方便的API和配置选项,可以自定义懒加载的行为和效果。 -
最佳实践:在使用图片懒加载时,可以考虑一些最佳实践。例如,设置一个占位符或加载中的动画,以提供更好的用户体验。另外,确保在不支持JavaScript的情况下仍然可用,并为可访问性提供替代文本(alt属性)。此外,对于移动设备,可以考虑使用响应式图片来适应不同的屏幕分辨率。
实现举例:
图片懒加载可以延迟图片的加载,只有当图片即将进入视口范围时才进行加载。这可以大大减轻页面的加载时间,并降低带宽消耗,提高了用户的体验。以下是一些常见的实现方法:
- Intersection Observer API
Intersection Observer API 是一种用于异步检查文档中元素与视口叠加程度的API。可以将其用于检测图片是否已经进入视口,并根据需要进行相应的处理。
const observer = new IntersectionObserver(function (entries) {
entries.forEach(function (entry) {
if (entry.isIntersecting) {
const lazyImage = entry.target
lazyImage.src = lazyImage.dataset.src
observer.unobserve(lazyImage)
}
})
})
const lazyImages = [...document.querySelectorAll('.lazy')]
lazyImages.forEach(function (image) {
observer.observe(image)
})
- 自定义监听器
或者,可以通过自定义监听器来实现懒加载。其中,应该避免在滚动事件处理程序中频繁进行图片加载,因为这可能会影响性能。相反,使用自定义监听器只会在滚动停止时进行图片加载。
function lazyLoad () {
const images = document.querySelectorAll('.lazy')
const scrollTop = window.pageYOffset
images.forEach((img) => {
if (img.offsetTop < window.innerHeight + scrollTop) {
img.src = img.dataset.src
img.classList.remove('lazy')
}
})
}
let lazyLoadThrottleTimeout
document.addEventListener('scroll', function () {
if (lazyLoadThrottleTimeout) {
clearTimeout(lazyLoadThrottleTimeout)
}
lazyLoadThrottleTimeout = setTimeout(lazyLoad, 20)
})
在这个例子中,我们使用了 setTimeout() 函数来延迟图片的加载,以避免在滚动事件的频繁触发中对性能的影响。
无论使用哪种方法,都需要为需要懒加载的图片设置占位符,并将未加载的图片路径保存在 data 属性中,以便在需要时进行加载。这些占位符可以是简单的 div 或样式类,用于预留图片的空间,避免页面布局的混乱。
<!-- 占位符示例 -->
<div class="lazy-placeholder" style="background-color: #ddd;height: 500px;"></div>
<!-- 图片示例 -->
<img class="lazy" data-src="path/to/image.jpg" alt="预览图" />
- 图片预加载
图片预加载是一种在网站或应用中提前加载图片资源的技术。它的主要目的是在用户实际需要加载图片之前,将其提前下载到浏览器缓存中。
图片预加载通常是在页面加载过程中或在特定事件触发前异步加载图片资源。 通过使用 JavaScript,可以在网页DOM元素中创建一个新的Image对象,并将要预加载的图片的URL赋值给该对象的src属性。 浏览器在加载过程中会提前下载这些图片,并将其缓存起来,以备将来使用。
图片预加载可以使用原生JavaScript实现,也可以使用现成的JavaScript库,如Preload.js、LazyLoad.js等。这些库提供了方便的API和配置选项,可以灵活地控制预加载的行为和效果。
实现图片预加载可以使用原生JavaScript或使用专门的JavaScript库。下面分别介绍两种方式的实现方法:
- 使用原生JavaScript实现图片预加载:
function preloadImage (url) {
return new Promise(function (resolve, reject) {
const img = new Image()
img.onload = resolve
img.onerror = reject
img.src = url
})
}
// 调用预加载函数
preloadImage('image.jpg')
.then(function () {
console.log('图片加载成功')
// 在此处可以执行加载成功后的操作,例如显示图片等
})
.catch(function () {
console.error('图片加载失败')
// 在此处可以执行加载失败后的操作,例如显示错误信息等
})
在上述代码中,我们定义了一个preloadImage函数,它使用Image对象来加载图片资源。通过onload事件和onerror事件来监听图片加载完成和加载错误的情况,并使用Promise对象进行异步处理。
- 使用JavaScript库实现图片预加载:
使用JavaScript库可以更简便地实现图片预加载,并提供更多的配置选项和功能。以下以Preload.js库为例进行说明:
首先,在HTML文件中引入Preload.js库:
<script src="preload.js"></script>
然后,在JavaScript代码中使用Preload.js库来进行图片预加载:
const preload = new createjs.LoadQueue()
preload.on('complete', handleComplete)
preload.on('error', handleError)
preload.loadFile('image.jpg')
function handleComplete () {
console.log('图片加载成功')
// 在此处可以执行加载成功后的操作,例如显示图片等
}
function handleError () {
console.error('图片加载失败')
// 在此处可以执行加载失败后的操作,例如显示错误信息等
}
在上述代码中,我们首先创建一个LoadQueue对象,并使用on方法来监听加载完成和加载错误的事件。然后使用loadFile方法来指定要预加载的图片资源的URL。
当图片加载完成时,handleComplete函数会被调用,我们可以在此处执行加载成功后的操作。当图片加载错误时,handleError函数会被调用,我们可以在此处执行加载失败后的操作。
以上是两种常用的实现图片预加载的方法,根据具体需求和项目情况选择合适的方式来实现图片预加载。
- 响应式加载图片
要在不同分辨率的设备上显示不同尺寸的图片,你可以使用<picture>元素和<source>元素来实现响应式图片。以下是一个示例:
<picture>
<source media="(min-width: 1200px)" srcset="large-image.jpg">
<source media="(min-width: 768px)" srcset="medium-image.jpg">
<source srcset="small-image.jpg">
<img src="fallback-image.jpg" alt="Fallback Image">
</picture>
在上面的示例中,<picture>元素内部有多个<source>元素,每个<source>元素通过srcset属性指定了对应分辨率下的图片链接。media属性可以用来指定在哪个分辨率下应用对应的图片。如果没有任何<source>元素匹配当前设备的分辨率,那么就会使用<img>元素的src属性指定的图片链接。
可以根据不同分辨率的设备,提供不同尺寸和质量的图片,以优化用户的视觉体验和页面加载性能。
有可以使用 webpack responsive-loader 来实现自动根据设备分辨率加载不同的倍图:
依赖安装:
npm install responsive-loader sharp --save-dev
webpack 配置示范
module.exports = {
entry: {
// ...
},
output: {
// ...
},
module: {
rules: [
{
test: /\.(jpe?g|png|webp)$/i,
use: [
{
loader: 'responsive-loader',
options: {
adapter: require('responsive-loader/sharp'),
sizes: [320, 640, 960, 1200, 1800, 2400],
placeholder: true,
placeholderSize: 20
}
}
]
}
]
}
}
在CSS中使用它(如果使用多个大小,则只使用第一个调整大小的图像)
.myImage {
background: url('myImage.jpg?size=1140');
}
@media (max-width: 480px) {
.myImage {
background: url('myImage.jpg?size=480');
}
}
导入图片到 JS 中:
import responsiveImage from 'img/myImage.jpg?sizes[]=300,sizes[]=600,sizes[]=1024,sizes[]=2048'
import responsiveImageWebp from 'img/myImage.jpg?sizes[]=300,sizes[]=600,sizes[]=1024,sizes[]=2048&format=webp'
// Outputs
// responsiveImage.srcSet => '2fefae46cb857bc750fa5e5eed4a0cde-300.jpg 300w,2fefae46cb857bc750fa5e5eed4a0cde-600.jpg 600w,2fefae46cb857bc750fa5e5eed4a0cde-600.jpg 600w ...'
// responsiveImage.images => [{height: 150, path: '2fefae46cb857bc750fa5e5eed4a0cde-300.jpg', width: 300}, {height: 300, path: '2fefae46cb857bc750fa5e5eed4a0cde-600.jpg', width: 600} ...]
// responsiveImage.src => '2fefae46cb857bc750fa5e5eed4a0cde-2048.jpg'
// responsiveImage.toString() => '2fefae46cb857bc750fa5e5eed4a0cde-2048.jpg'
// ...
// <picture>
// <source srcSet={responsiveImageWebp.srcSet} type='image/webp' sizes='(min-width: 1024px) 1024px, 100vw'/>
// <img
// src={responsiveImage.src}
// srcSet={responsiveImage.srcSet}
// width={responsiveImage.width}
// height={responsiveImage.height}
// sizes='(min-width: 1024px) 1024px, 100vw'
// loading="lazy"
// />
// </picture>
// ...
- 渐进式加载图片
实现渐进式加载的主要思想是先加载一张较低分辨率的模糊图片,然后逐步加载更高分辨率的图片。
下面是实现渐进式加载图片的一般步骤:
-
创建一张模糊的低分辨率图片。可以使用图片处理工具将原始图片进行模糊处理,或者使用低分辨率的缩略图作为初始图片。
-
使用
<img>标签将低分辨率的图片设置为src属性。这将立即加载并显示这张低分辨率的图片。 -
在加载低分辨率图片时,同时加载高分辨率的原始图片。可以将高分辨率图片的URL设置为
data-src等自定义属性,或者使用JavaScript动态加载高清图片。 -
使用JavaScript监听图片的加载事件,在高分辨率图片加载完成后,将其替换低分辨率图片的
src属性,以实现渐进式加载的效果。
下面是一个示例代码,演示了如何实现渐进式加载图片:
<!-- HTML -->
<img src="blur-image.jpg" data-src="high-res-image.jpg" alt="Image">
<script>
// JavaScript
const image = document.querySelector('img');
// 监听高分辨率图片加载完成事件
image.addEventListener('load', () => {
// 替换低分辨率图片的src属性
image.src = image.dataset.src;
});
</script>
在上面的示例中,一开始会显示一张模糊的低分辨率图片,然后在高分辨率图片加载完成后,将其替换为高分辨率图片,实现了渐进式加载的效果。
渐进式加载图片可以减少用户等待时间,提供更好的用户体验。然而,需要注意的是,为了实现渐进式加载,需要额外加载高分辨率的图片,这可能会增加页面加载时间和网络带宽消耗。因此,开发者需要在性能和用户体验之间进行权衡,并根据实际情况进行选择和优化。
css加载会造成阻塞吗
css加载会造成阻塞吗?
js执行会阻塞DOM树的解析和渲染,那么css加载会阻塞DOM树的解析和渲染吗? 为了完成本次测试,先来科普一下,如何利用chrome来设置下载速度
打开chrome控制台(按下F12),可以看到下图,重点在我画红圈的地方
-
点击我画红圈的地方(No throttling),会看到下图,我们选择GPRS这个选项
-
这样,我们对资源的下载速度上限就会被限制成20kb/s,好,那接下来就进入我们的正题
css加载会阻塞DOM树的解析渲染吗?
<!DOCTYPE html>
<html lang="en">
<head>
<title>css阻塞</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
h1 {
color: red !important
}
</style>
<script>
function h () {
console.log(document.querySelectorAll('h1'))
}
setTimeout(h, 0)
</script>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
</head>
<body>
<h1>这是红色的</h1>
</body>
</html>
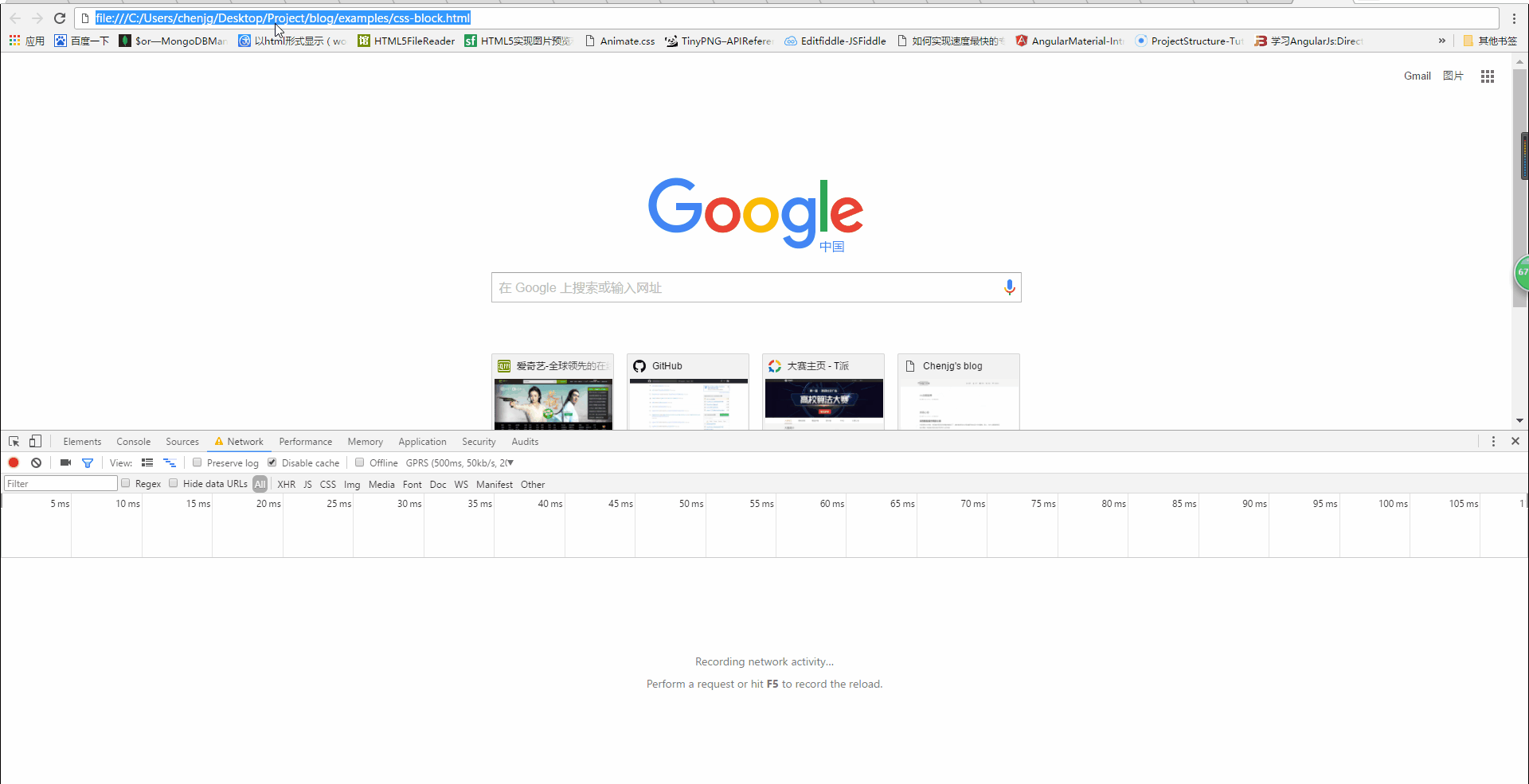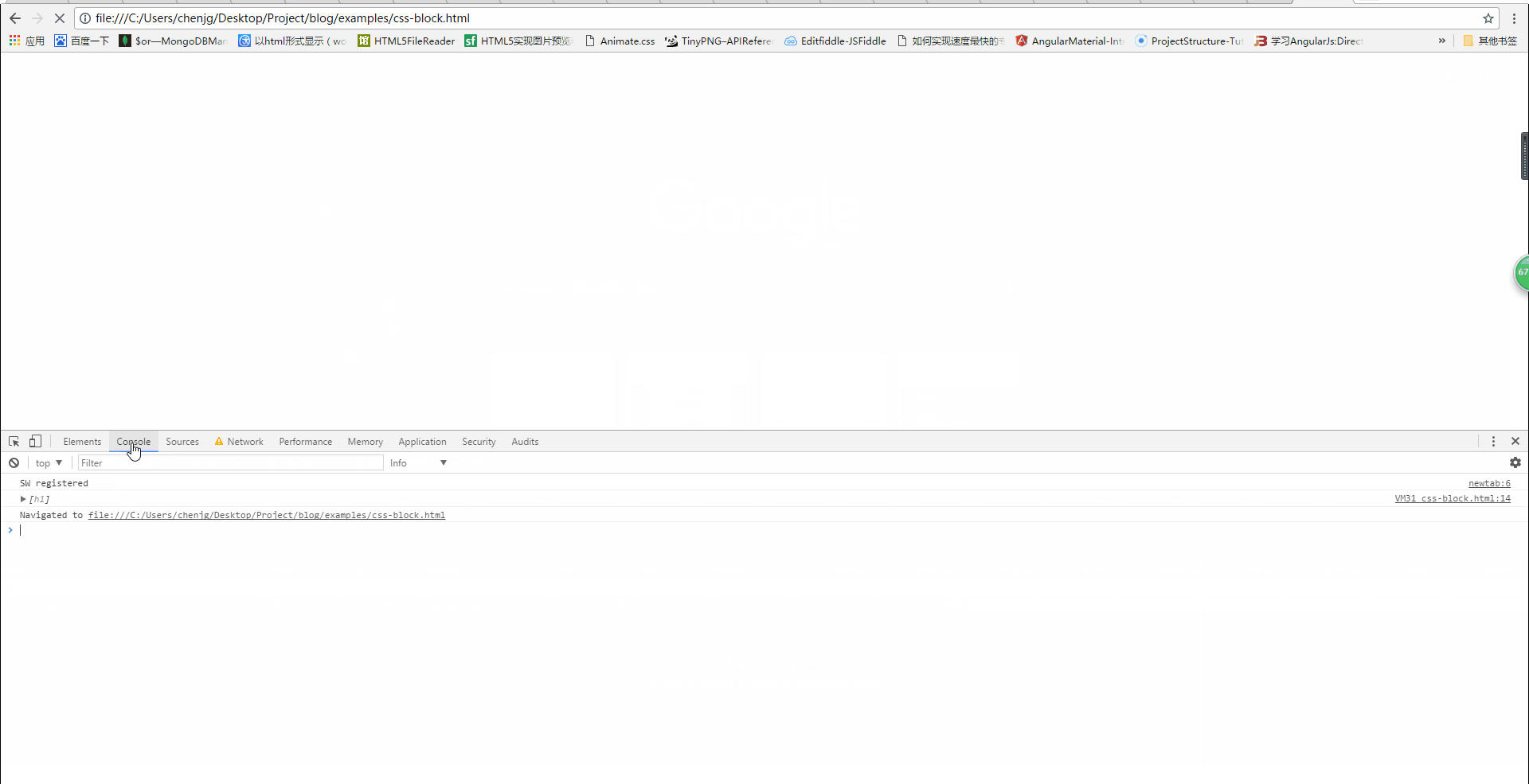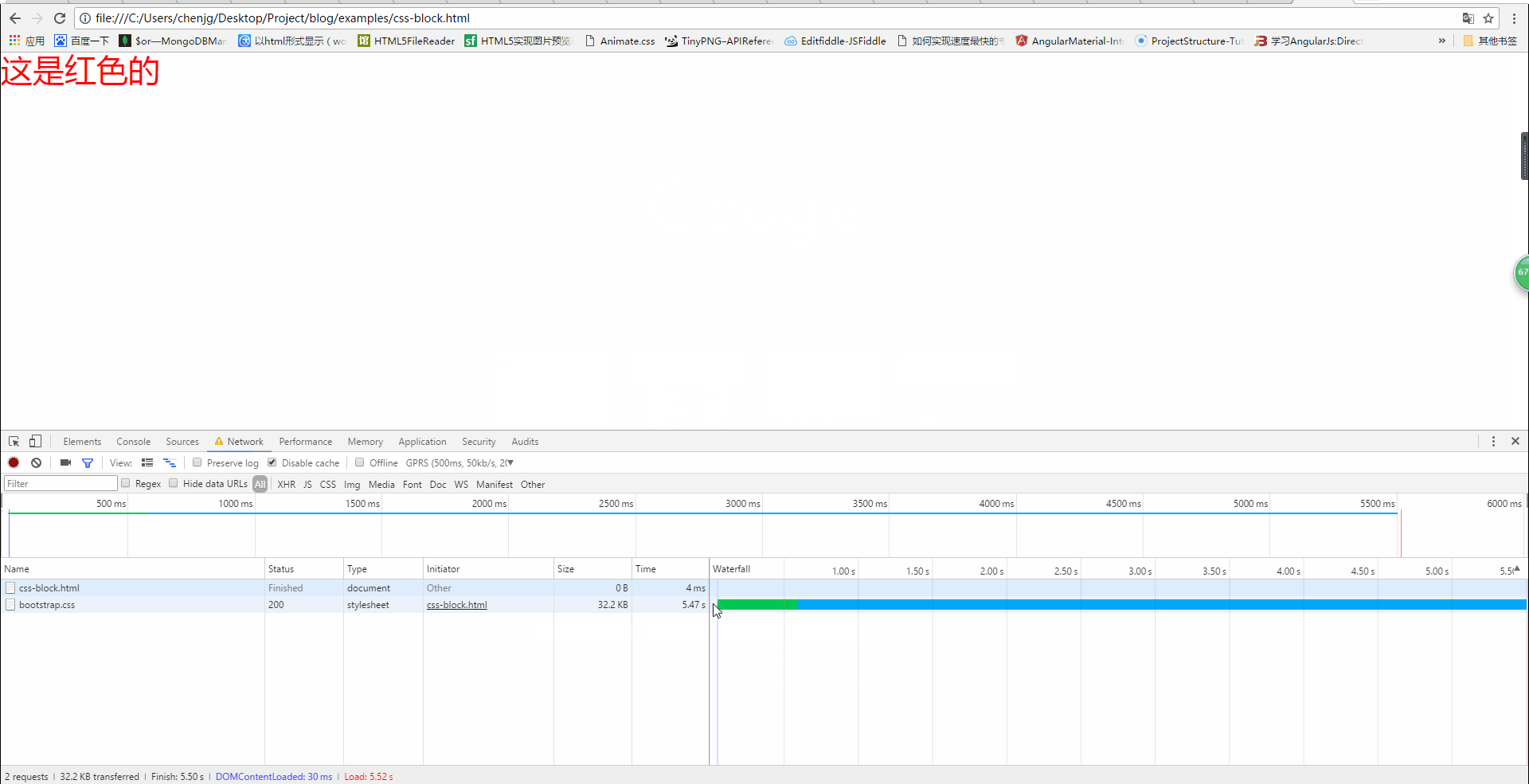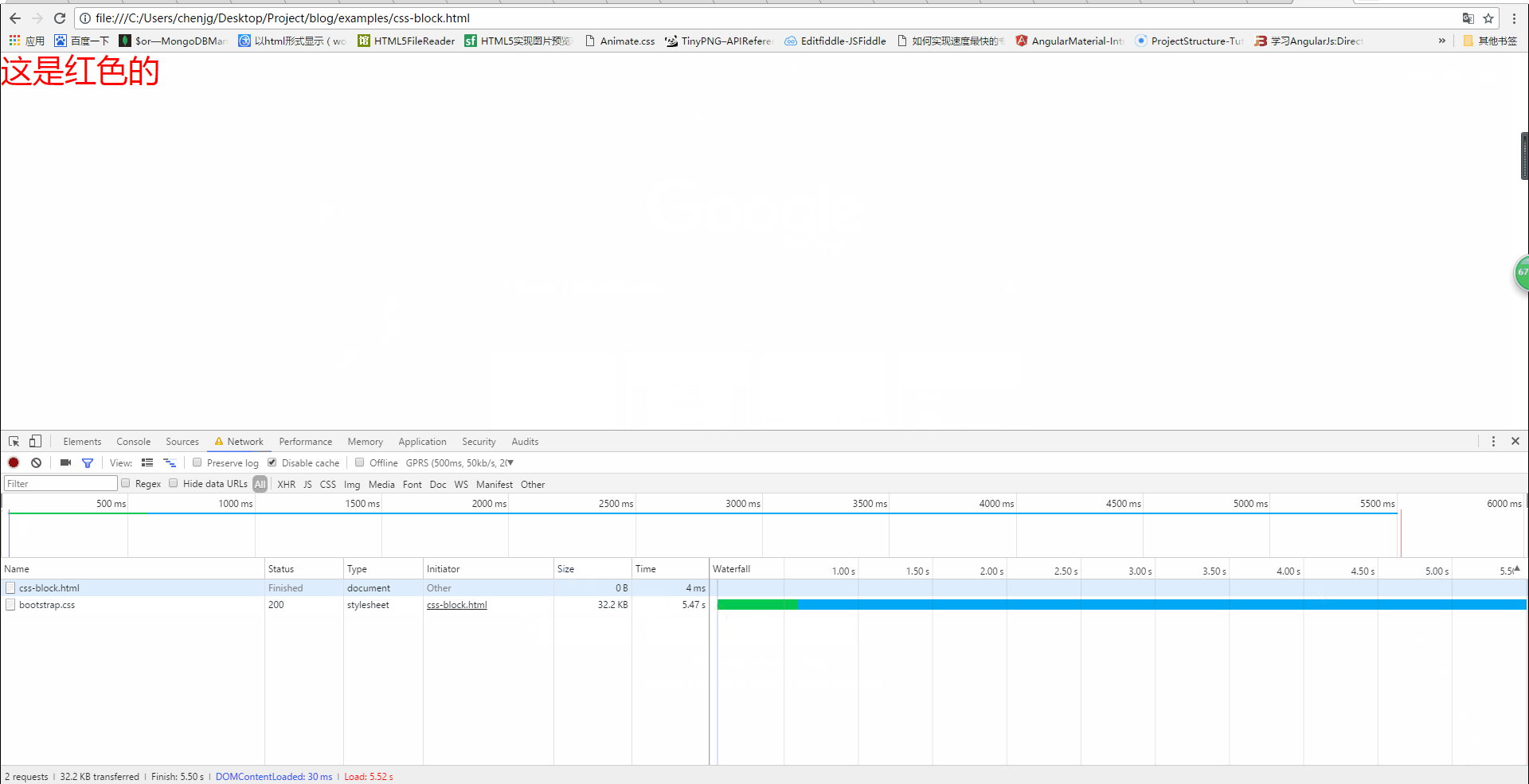
假设: css加载会阻塞DOM树解析和渲染
假设下的结果: 在bootstrap.css还没加载完之前,下面的内容不会被解析渲染。那么我们一开始看到的应该是白屏,h1不会显示出来。
并且此时console.log的结果应该是一个空数组。
实际结果:如下图
css会阻塞DOM树解析?
由上图我们可以看到,当bootstrap.css还没加载完成的时候,h1并没有显示,但是此时控制台输出如下

可以得知,此时DOM树至少已经解析完成到了h1那里,而此时css还没加载完成,也就说明,css并不会阻塞DOM树的解析。
css加载会阻塞DOM树渲染?
由上图,我们也可以看到,当css还没加载出来的时候,页面显示白屏,直到css加载完成之后,红色字体才显示出来,也就是说, 下面的内容虽然解析了,但是并没有被渲染出来。所以,css加载会阻塞DOM树渲染。
个人对这种机制的评价
其实我觉得,这可能也是浏览器的一种优化机制。因为你加载css的时候, 可能会修改下面DOM节点的样式,如果css加载不阻塞DOM树渲染的话,那么当css加载完之后, DOM树可能又得重新重绘或者回流了,这就造成了一些没有必要的损耗。所以干脆就先把DOM树的结构先解析完,把可以做的工作做完, 然后等你css加载完之后,在根据最终的样式来渲染DOM树,这种做法性能方面确实会比较好一点。
css加载会阻塞js运行吗?
由上面的推论,我们可以得出,css加载不会阻塞DOM树解析,但是会阻塞DOM树渲染。那么,css加载会不会阻塞js执行呢?
<!DOCTYPE html>
<html lang="en">
<head>
<title>css阻塞</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<script>
console.log('before css')
var startDate = new Date()
</script>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
</head>
<body>
<h1>这是红色的</h1>
<script>
var endDate = new Date()
console.log('after css')
console.log('经过了' + (endDate -startDate) + 'ms')
</script>
</body>
</html>
假设: css加载会阻塞后面的js运行
预期结果: 在link后面的js代码,应该要在css加载完成后才会运行
实际结果:
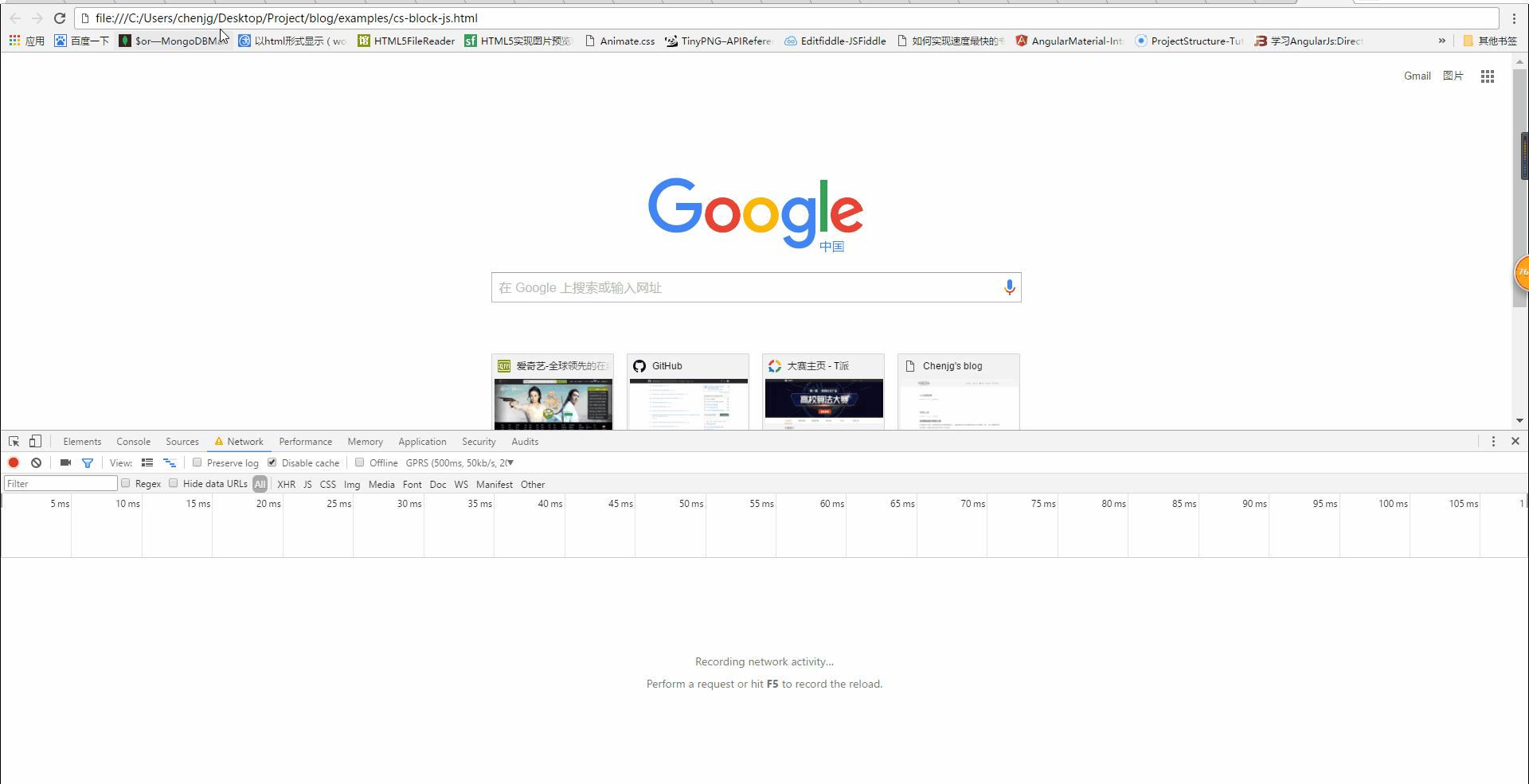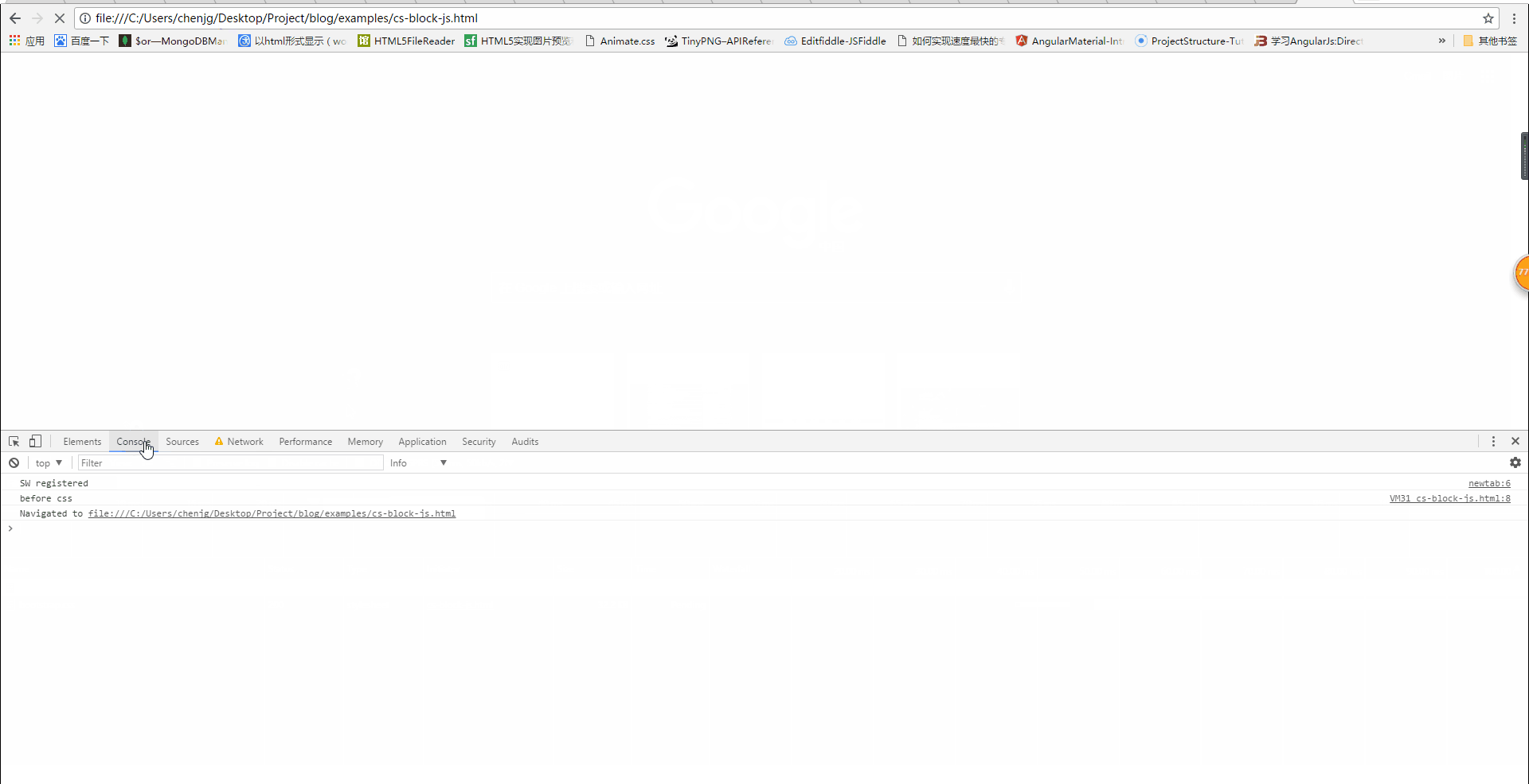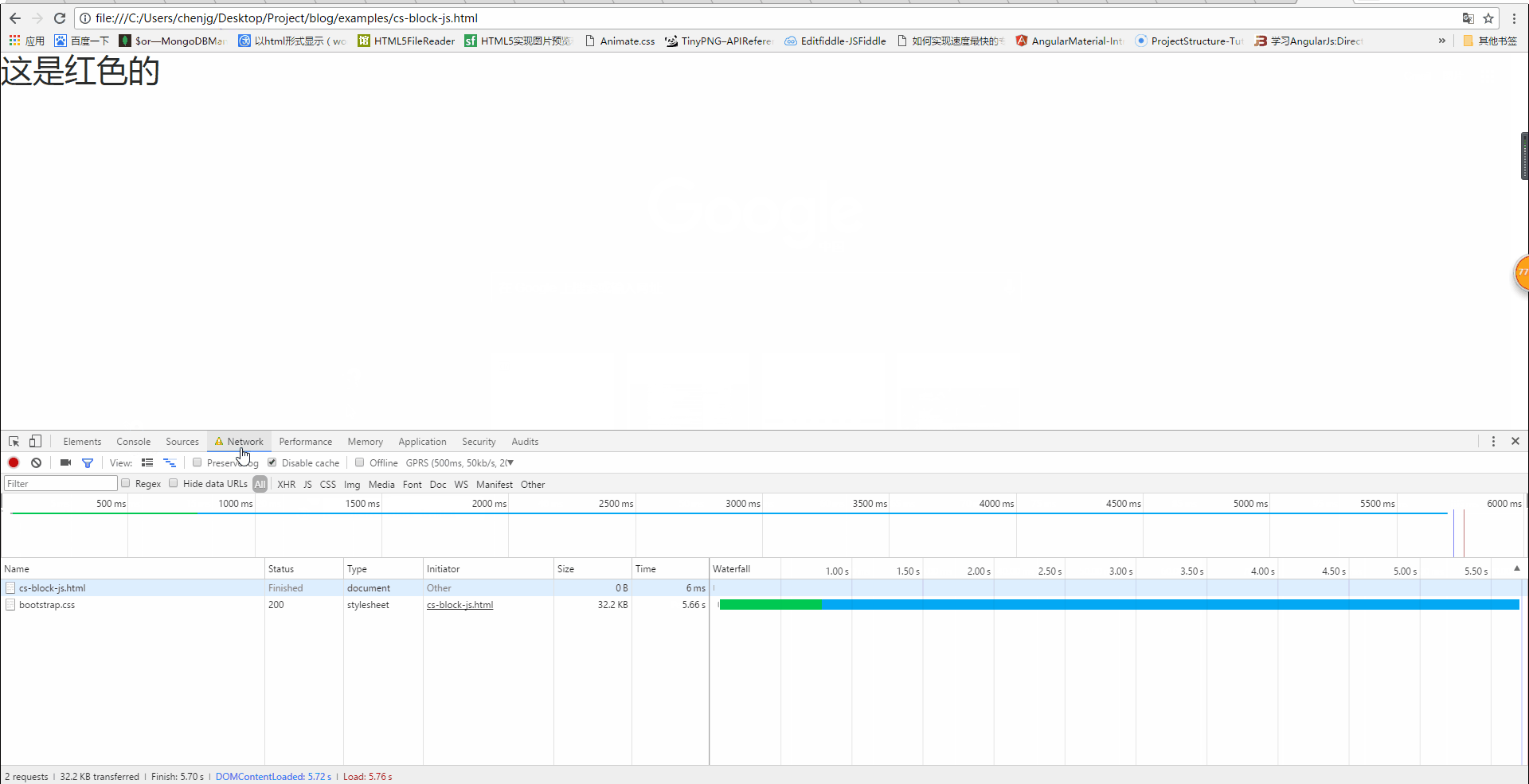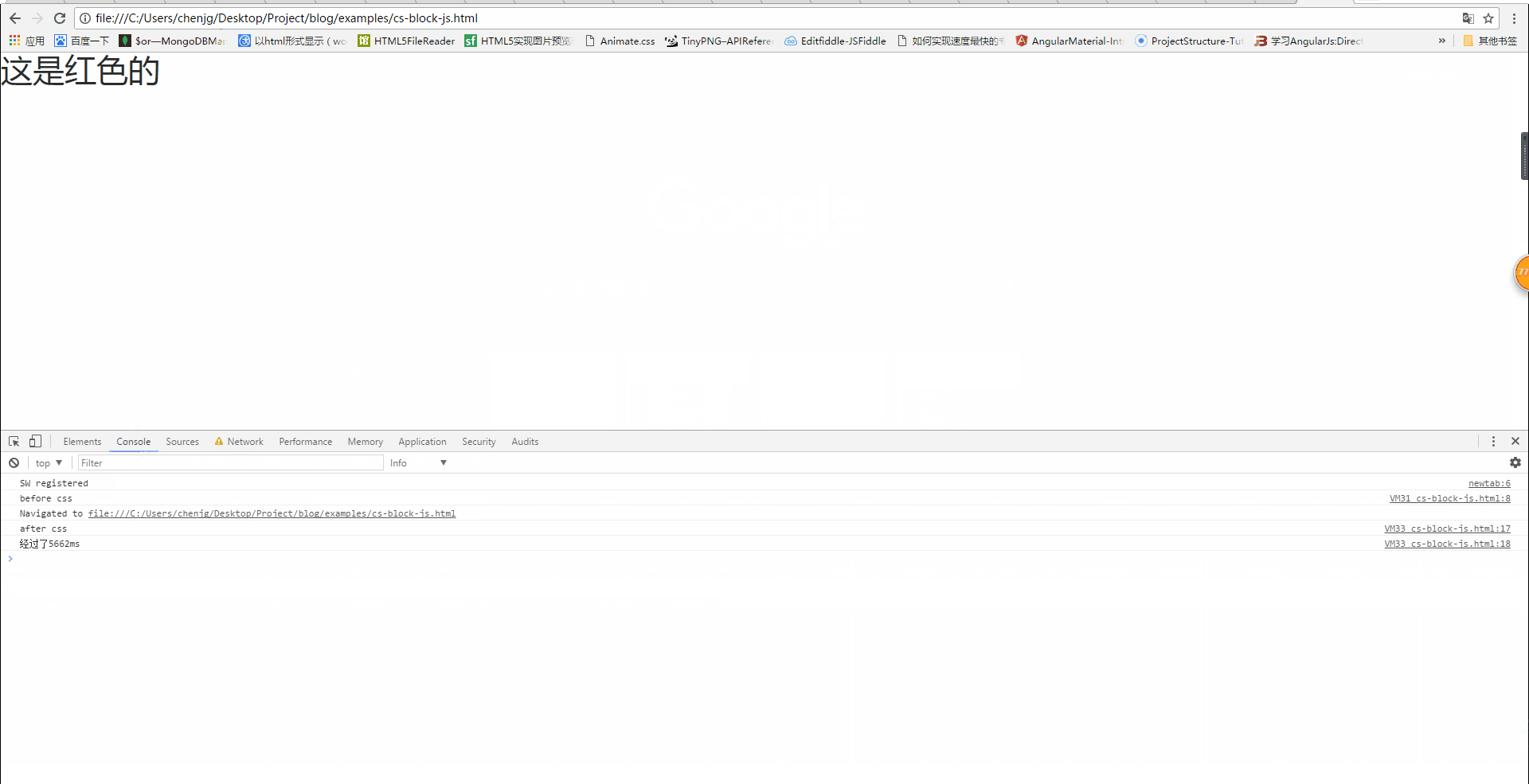
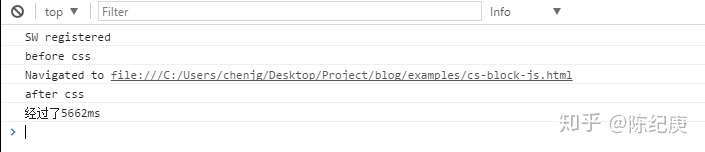
由上图我们可以看出,位于css加载语句前的那个js代码先执行了,
但是位于css加载语句后面的代码迟迟没有执行,直到css加载完成后,它才执行。
这也就说明了,css加载会阻塞后面的js语句的执行。详细结果看下图(css加载用了5600+ms):
结论
由上所述,我们可以得出以下结论:
- css加载不会阻塞DOM树的解析
- css加载会阻塞DOM树的渲染
- css加载会阻塞后面js语句的执行
因此,为了避免让用户看到长时间的白屏时间,我们应该尽可能的提高css加载速度,比如可以使用以下几种方法:
- 使用CDN(因为CDN会根据你的网络状况,替你挑选最近的一个具有缓存内容的节点为你提供资源,因此可以减少加载时间)
- 对css进行压缩(可以用很多打包工具,比如webpack,gulp等,也可以通过开启gzip压缩)
- 合理的使用缓存(设置cache-control,expires,以及E-tag都是不错的,不过要注意一个问题,就是文件更新后,你要避免缓存而带来的影响。其中一个解决防范是在文件名字后面加一个版本号)
- 减少http请求数,将多个css文件合并,或者是干脆直接写成内联样式(内联样式的一个缺点就是不能缓存)
其他补充
浏览器渲染是合并dom和cssom的过程,和js完全不一样。 浏览器实现是,尽量等待dom和cssom解析完成,再开始合并渲染。 如果dom解析完成但是css文件超时,或者css太慢,浏览器也会先渲染dom,等css下载完成再另一次渲染。 而为什么会阻塞js,大部分原因都是因为js一般是在页面load完成之后才执行。 如果css都没加载完成js自然不会执行。以上属个人见解,实际情况自行测试。
浏览器对CSS阻塞渲染有两种处理方式,要么等css解析完一起渲染,chrome就是这么做的,但是会造成白屏; 要么先把无样式的dom渲染出来等css解析好了再渲染一次,Firefox就是这么做的,但是会造成无样式内容闪烁。
参考文章
当浏览器遇到一个 <link> 标签时,它会停止解析 HTML 并发出一个单独的网络请求去加载外部样式表。
这意味着,如果样式表很大或者网络速度很慢,它将阻止页面的渲染。阻止 CSS 渲染可能会导致页面看起来很糟糕,用户无法立即看到页面内容。
有一些方法可以防止或减轻 CSS 阻塞渲染:
-
内联样式:使用内联样式而不是外部样式表,将样式放在页面的顶部,这样 HTML 就能很快地被渲染出来。
-
通过媒体查询加载符合指定媒体类型或条件的样式表。这样不会影响未满足条件的设备或屏幕渲染结果。
-
使用
rel="preload"或者rel="prefetch"预加载样式表,这有助于在页面渲染过程中尽早加载样式表,提高页面加载速度。 -
通过使用 JavaScript 动态加载样式表,可以实现延迟加载和异步加载。这可以帮助查看者能够看到尽快的内容,然后在不影响查看体验的前提下加载样式表。
-
考虑压缩和优化您的 CSS 文件,以使代码更加紧凑、加载更快。
-
对已经被加载的字体和图片,使用 CSS Sprites 技术合并到一个文件或者减少 HTTP 请求数量。
SPA首屏加载速度慢的怎么解决
可以参考下面的文档:
影响首屏可能得因素
- 网络延时问题
- 资源文件体积是否过大
- 资源是否重复发送请求去加载了
- 加载脚本的时候,渲染内容堵塞了
解决方案
- 减小入口文件积
- 静态资源本地缓存
- UI框架按需加载
- 图片资源的压缩
- 组件重复打包
- 开启 GZip 压缩
- 使用 SSR
- 启用 CDN 加速
如何优化 DOM 树解析过程
以下是一些优化DOM树解析的方法:
-
减少DOM元素数量:尽可能减少页面上的DOM元素数量,可以通过合并或删除不必要的元素、使用CSS样式代替多个元素等方式来实现。
-
使用语义化的HTML结构:使用合适的HTML标签和语义化的结构,可以提高解析的效率,减少解析错误的可能性。
-
避免深层嵌套的DOM结构:避免过深的DOM嵌套,因为深层嵌套会增加DOM节点的数量,解析和渲染的时间也会增加。
-
使用外部脚本和样式表:将JavaScript代码和CSS样式表尽可能地外部引入,可以避免在解析过程中阻塞DOM树的构建。
-
使用异步加载脚本:将需要的脚本使用async或defer属性进行异步加载,可以让DOM树的解析和脚本加载并行进行,提高解析的效率。
-
优化CSS选择器:避免使用复杂的CSS选择器,因为复杂的选择器需要进行更多的计算和匹配,会影响解析的速度。
-
批量修改DOM:避免对DOM进行频繁的修改,尽量使用批量操作的方式来修改DOM,可以减少浏览器的重排和重绘。
-
使用文档片段(DocumentFragment):将需要频繁操作的DOM元素先添加到文档片段中,然后再一次性地将文档片段添加到文档中,可以减少重排和重绘的次数。
-
使用虚拟DOM:在一些前端框架中,使用虚拟DOM可以减少对真实DOM的直接操作,通过比较虚拟DOM树的差异来进行最小化的DOM操作,从而提高效率。
常见图片懒加载
图片懒加载可以延迟图片的加载,只有当图片即将进入视口范围时才进行加载。这可以大大减轻页面的加载时间,并降低带宽消耗,提高了用户的体验。以下是一些常见的实现方法:
- Intersection Observer API
Intersection Observer API 是一种用于异步检查文档中元素与视口叠加程度的API。可以将其用于检测图片是否已经进入视口,并根据需要进行相应的处理。
const observer = new IntersectionObserver(function (entries) {
entries.forEach(function (entry) {
if (entry.isIntersecting) {
const lazyImage = entry.target
lazyImage.src = lazyImage.dataset.src
observer.unobserve(lazyImage)
}
})
})
const lazyImages = [...document.querySelectorAll('.lazy')]
lazyImages.forEach(function (image) {
observer.observe(image)
})
- 自定义监听器
或者,可以通过自定义监听器来实现懒加载。其中,应该避免在滚动事件处理程序中频繁进行图片加载,因为这可能会影响性能。相反,使用自定义监听器只会在滚动停止时进行图片加载。
function lazyLoad () {
const images = document.querySelectorAll('.lazy')
const scrollTop = window.pageYOffset
images.forEach((img) => {
if (img.offsetTop < window.innerHeight + scrollTop) {
img.src = img.dataset.src
img.classList.remove('lazy')
}
})
}
let lazyLoadThrottleTimeout
document.addEventListener('scroll', function () {
if (lazyLoadThrottleTimeout) {
clearTimeout(lazyLoadThrottleTimeout)
}
lazyLoadThrottleTimeout = setTimeout(lazyLoad, 20)
})
在这个例子中,我们使用了 setTimeout() 函数来延迟图片的加载,以避免在滚动事件的频繁触发中对性能的影响。
无论使用哪种方法,都需要为需要懒加载的图片设置占位符,并将未加载的图片路径保存在 data 属性中,以便在需要时进行加载。这些占位符可以是简单的 div 或样式类,用于预留图片的空间,避免页面布局的混乱。
<!-- 占位符示例 -->
<div class="lazy-placeholder" style="background-color: #ddd;height: 500px;"></div>
<!-- 图片示例 -->
<img class="lazy" data-src="path/to/image.jpg" alt="预览图" />
总体来说,图片懒加载是一种这很简单,但非常实用的优化技术,能够显著提高网页的性能和用户体验。
react 优化
两种方式可实现:
- 使用 React 中 Suspense,lazy
- 使用 react-loadable
React 中 Suspense,lazy
应用的组件需要使用 lazy 的方式引入, 且使用 Suspense 包裹异步加载的组件
import { Route, Switch } from 'react-router-dom';
const MainCom = lazy(() => import('../views/main/maincom'));
class RouterConfig extends React.Component {
render() {
return (
<Suspense fallback={<div> 加载中 </div>}>
<Switch>
...
<Route exact path="/" component={MainCom} />
...
</Switch>
</Suspense>
)
}
}
export default RouterConfig;
react-loadable
import { Route, Switch } from 'react-router-dom';
import Loadable from 'react-loadable';
const logincom = Loadable({
loader: () => import('../views/login/login'),
loading() {
return <div>正在加载</div>
},
})
class RouterConfig extends React.Component {
render() {
return (
<Suspense fallback={<div> 加载中 </div>}>
<Switch>
...
<Route exact path="/" component={logincom} />
...
</Switch>
</Suspense>
)
}
}
export default RouterConfig;
受控性组件颗粒化 ,独立请求服务渲染单元
可控性组件颗粒化,独立请求服务渲染单元是笔者在实际工作总结出来的经验。目的就是避免因自身的渲染更新或是副作用带来的全局重新渲染。
大概思路是这样子的:
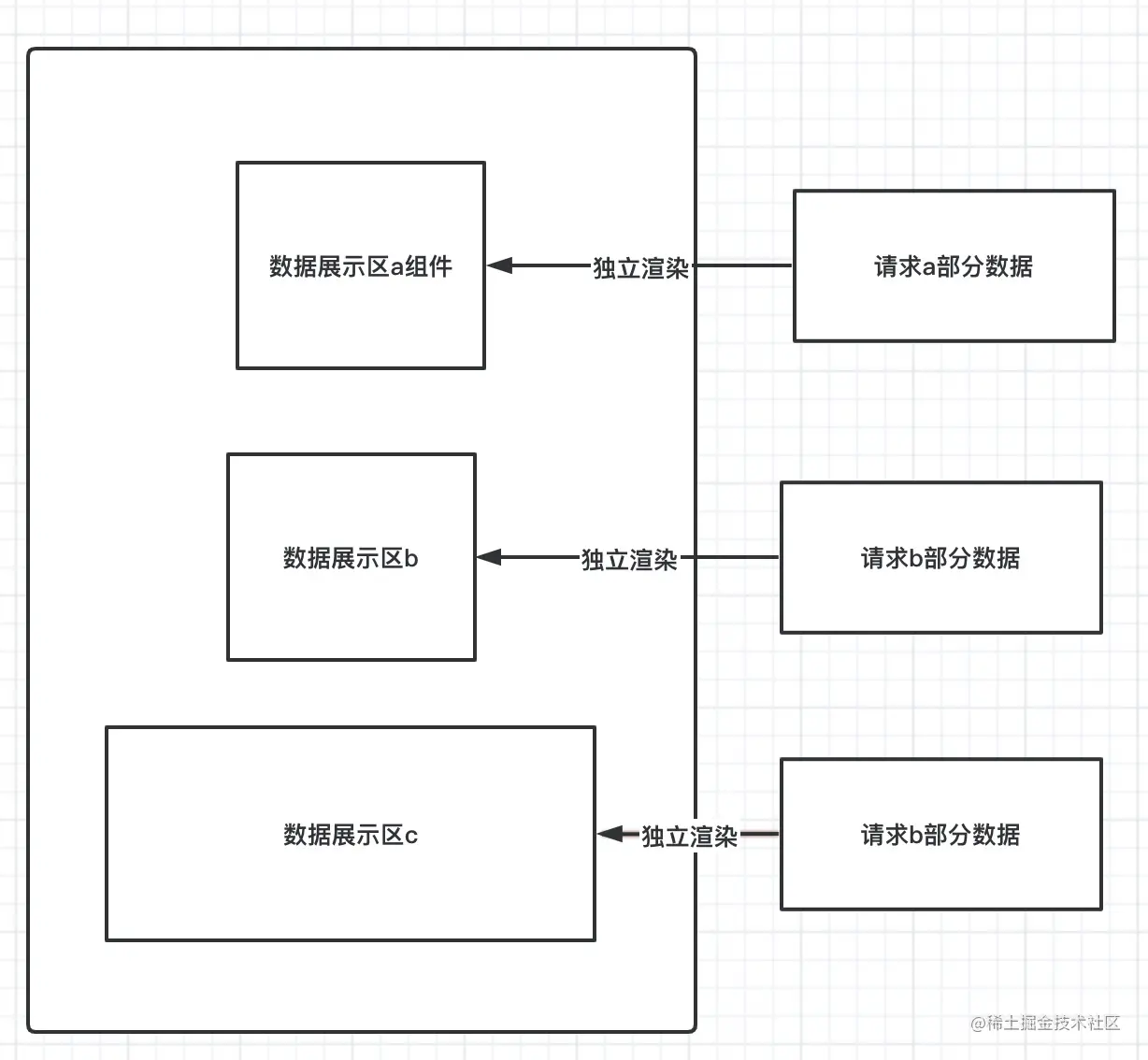
拆分需要单独调用后端接口的细小组件,建立独立的数据请求和渲染,这种依赖数据更新 -> 视图渲染的组件,能从整个体系中抽离出来 ,好处我总结有以下几个方面。
-
可以避免父组件的冗余渲染 ,react的数据驱动,依赖于 state 和 props 的改变,改变state 必然会对组件 render 函数调用,如果父组件中的子组件过于复杂,一个自组件的 state 改变,就会牵一发动全身,必然影响性能,所以如果把很多依赖请求的组件抽离出来,可以直接减少渲染次数。
-
可以优化组件自身性能,无论从class声明的有状态组件还是fun声明的无状态,都有一套自身优化机制,无论是用shouldupdate 还是用 hooks中 useMemo useCallback ,都可以根据自身情况,定制符合场景的渲条 件,使得依赖数据请求组件形成自己一个小的,适合自身的渲染环境。
-
能够和redux ,以及redux衍生出来 redux-action , dva,更加契合的工作,用 connect 包裹的组件,就能通过制定好的契约,根据所需求的数据更新,而更新自身,而把这种模式用在这种小的,需要数据驱动的组件上,就会起到物尽其用的效果。
shouldComponentUpdate ,PureComponent 和 React.memo ,immetable.js/immer.js 助力性能调优
PureComponent 和 React.memo
React.PureComponent 通过props和state的浅对比来实现 shouldComponentUpate()。如果对象包含复杂的数据结构(比如对象和数组) ,他会浅比较,如果深层次的改变,是无法作出判断的,React.PureComponent 认为没有变化,而没有渲染试图。
react.memo 和 PureComponent 功能类似 ,react.memo 作为第一个高阶组件,第二个参数 可以对props 进行比较 ,和shouldComponentUpdate不同的, 当第二个参数返回 true 的时候,证明props没有改变,不渲染组件,反之渲染组件。
shouldComponentUpdate
使用 shouldComponentUpdate() 以让React知道当state或props的改变是否影响组件的重新render,默认返回ture,返回false时不会重新渲染更新,而且该方法并不会在初始化渲染或当使用 forceUpdate() 时被调用。
immetable.js/immer.js
immetable.js 是Facebook 开发的一个js库,可以提高对象的比较性能,像之前所说的pureComponent 只能对对象进行浅比较,,对于对象的数据类型,却束手无策,所以我们可以用 immetable.js 配合 shouldComponentUpdate 或者 react.memo来使用。immutable 中 我们用react-redux来简单举一个例子,如下所示 数据都已经被 immetable.js处理。
import { is } from 'immutable'
const GoodItems = connect(state =>
({ GoodItems: filter(state.getIn(['Items', 'payload', 'list']), state.getIn(['customItems', 'payload', 'list'])) || Immutable.List(), })
// 此处省略很多代码~~~~~~ */
)(memo(({ Items, dispatch, setSeivceId }) => {
// */
}, (pre, next) => is(pre.Items, next.Items)))
通过 is 方法来判断,前后Items(对象数据类型)是否发生变化。
immer 是 mobx 的作者写的一个 immutable 库,核心实现是利用 ES6 的 proxy,几乎以最小的成本实现了 js 的不可变数据结构,简单易用、体量小巧、设计巧妙,满足了我们对 JS 不可变数据结构的需求。
具体使用可见: 资料
hooks 组件中, 常使用 useMemo、useCallback、useRef 等方式方式重复申明
每次点击button的时候,都会执行Index函数。handerClick1 , handerClick2,handerClick3都会重新声明。这种函数的重复申明, 会使得子组件每次都是拿到的新的应用对象, 会导致 memo 直接失效。
function Index() {
const [number, setNumber] = useState(0)
const [handerClick1, handerClick2, handerClick3] = useMemo(() => {
const fn1 = () => {
// 一些操作 */
}
const fn2 = () => {
// 一些操作 */
}
const fn3 = () => {
// 一些操作 */
}
return [fn1, fn2, fn3]
}, []) // 只有当数据里面的依赖项,发生改变的时候,才会重新声明函数。 */
return <div>
<a onClick={handerClick1}>点我有惊喜1</a>
<a onClick={handerClick2}>点我有惊喜2</a>
<a onClick={handerClick3}>点我有惊喜3</a>
<button onClick={() => setNumber(number + 1)}> 点击 {number} </button>
</div>
}
推荐使用 ahooks - usePersistFn、useMemoizedFn 其实现也非常简单, 就是将函数的应用绑定在了 ref 上
function usePersistFn(fn, deps) {
const fnRef = useRef();
useEffect(() => {
fnRef.current = fn;
}, [fn, ...deps]);
return useCallback(() => {
return fnRef.current();
}, [fnRef]);
}
警惕 context 陷阱
使用Context可以避免的组件的层层props嵌套的问题。但是它使用consumer拿值时,会多一层组件。但得益于 useContext hook 我们可以不使用consumer组件。直接拿到值,直观。一般的使用场景,如那拿全局的class前缀,或者国际化,Ui主题颜色等。
但是当 Provider 的 value 值发生变化时,它内部的所有消费组件都会重新渲染。Provider 及其内部 consumer 组件都不受制于 shouldComponentUpdate、memo 等函数,因此当 consumer 组件在其祖先组件退出更新的情况下也能更新。
使用 createContext 和 useContext 的时候, 尽量从顶层往下传递的数据是不可变的数据, 否则会引起整个链路层级的渲染。
此处推荐 使用 recoil, 由 facebook 官方出品, 使用语法非常简单, 跟 context 很类似。
dom 渲染能使用 GPU 加速吗?
只有部分情况可以使用 GPU 加速渲染。浏览器将 DOM 元素转换为图层(Layer),然后将图层绘制到屏幕上。在某些情况下,这些图层可以使用 GPU 加速,从而提高渲染性能。
浏览器将具有以下属性之一的元素视为单独的图层:
- 使用 CSS 3D 变换或透视属性的元素
- 使用 CSS 滤镜的元素
- 使用 will-change 属性显式指定的元素
- 使用
<video>、<canvas>、<webgl>或其他可加速元素的元素
将元素分层后,浏览器可以将其提交到 GPU 来处理,从而加快渲染速度。这样可以避免使用 CPU 进行复杂的布局和绘制操作,而 GPU 可以更快地处理这些操作。
canvas 性能为何会比 html/css 好?
Canvas 和 HTML/CSS 是两种不同的技术,各自有着自己的优势和适用场景。
Canvas 是一种基于 JavaScript 的 2D/3D 绘图技术,它允许开发者直接操作像素,可以实现复杂的图形、动画和游戏等效果,其性能比 HTML/CSS 要好的原因主要有以下几点:
-
直接操作像素:Canvas 允许开发者直接操作像素,不需要经过复杂的 DOM 计算和渲染,能够更快地响应用户操作,提高交互的流畅性。
-
GPU 加速:现代浏览器已经对 Canvas 进行了 GPU 加速,使得 Canvas 能够更加高效地处理大量的图形和动画。
-
没有样式计算:与 HTML/CSS 不同,Canvas 不需要进行样式计算和布局,能够减少浏览器的重绘和重排,从而提高渲染性能。
-
可以缩放和裁剪:Canvas 可以进行缩放和裁剪操作,能够适应不同的屏幕分辨率和大小,同时也可以减少不必要的绘图计算。
总之,Canvas 能够更加高效地处理大量的图形和动画,适用于需要复杂绘图和动画的场景,而 HTML/CSS 更适合处理文本和静态布局,适用于构建 Web 页面。
- 优势:
- 矢量图形:SVG 使用矢量图形描述,图形会根据缩放和放大而保持清晰,适用于需要无损放大的情况。
- 文本处理:SVG 对于文本处理较好,可以方便地添加和编辑文本。
- 简单图形绘制:SVG 支持直接绘制基本图形,如矩形、圆形、线条等,方便快速绘制简单图表。
- 劣势:
- 复杂图形处理:当图形复杂度较高时,SVG 的性能会受到影响,特别是在处理大量数据时。
- 动画效果:SVG 的动画效果相对较弱,复杂的动画效果可能导致性能下降。
Canvas:
- 优势:
- 像素级控制:Canvas 提供了像素级别的控制,可以绘制复杂的图形和图表。
- 性能较好:Canvas 可以通过 JavaScript 直接操作像素,适用于处理大量数据和复杂图形的场景。
- 动画效果:Canvas 可以通过 JavaScript 控制每一帧的绘制,实现复杂的动画效果。
- 劣势:
- 缩放和放大:Canvas 绘制的图形是像素级别的,当需要缩放和放大时会导致图形模糊。
- 文本处理:相对于 SVG,Canvas 对于文本处理较为复杂,需要手动进行字体设置和绘制。
WebGL(Web Graphics Library):
- 优势:
- 3D 图形渲染:WebGL 可以进行硬件加速的 3D 图形渲染,适用于创建复杂的 3D 场景和效果。
- 性能优异:WebGL 可以充分利用 GPU 的并行计算能力,具有较好的性能表现。
- 劣势:
- 学习成本高:WebGL 使用 OpenGL ES 的接口,对于开发者要求一定的图形学和计算机图形学的知识。
- 兼容性问题:WebGL 需要浏览器支持,并且在某些设备和浏览器上可能存在兼容性问题。
综上所述,选择适合的技术取决于具体的需求,如图形复杂性、数据量大小、动画效果的需求、对文本处理的要求等。在实际开发中,也可以结合使用不同的技术来满足不同的需求。
表格对比
| 特性 | Canvas | SVG |
|---|---|---|
| 图形质量 | 像素级别的图形,适合绘制大量复杂动态的图形 | 矢量图,图形不会失真,适合绘制静态图形 |
| 图形渲染 | 快速渲染,适合处理大量图形数据 | 慢速渲染,适合处理小规模静态图形 |
| 交互性 | 事件处理复杂,需要手动编写交互逻辑 | 事件处理简单,内置事件处理机制 |
| 动画效果 | 动画效果需要手动实现,实现复杂动画困难 | 内置 SMIL 动画支持,可实现较复杂动画效果 |
| 浏览器支持 | 除 IE8 及以下版本外,其他浏览器都支持 | 除 IE9 及以下版本外,其他浏览器都支持 |
| 适用场景 | 处理大量动态图形,如游戏开发、数据可视化等 | 绘制简单静态图形,如图标、线条、文字等 |